

ELK, 3 ayrı open source yapının birleşmesiyle oluşmus yine open source bir hizmettir. Beats aracılığıyla loglar toplanarak Logstash aracımıza aktarılır. Burada loglar derlenir, yapılması istenilen şekle dönüştürülür. Bu logları indexleyerek aranabilir ve analiz edilebilir hale getirmek için ise Elasticsearch kullanılır. Tüm bu yapılan işlemleri ise Kibana arayüzü görselleştirir.

Bu yazı serisinde bu araçları tek tek incelemek istiyorum. Haydi Elasticsearch üzerine aldığım notlar ile başlayalım.
Elasticsearch
Uygulamalar üzerinden toplanan verilerin analizi ve içerik arama yapmamızı sağlayan bir arama motorudur. Elasticsearch tamamen Java dilinde yazılmıştır. Dağıtık mimariye sahiptir ve açık kaynak kodludur. Elasticsearch indexler üzerinden arama yaparak çok hızlı sonuçlar elde etmektedir. Bunun yanında sorgular üzerinde analizler , skorlamalar yapmaya da imkan tanır. Dağıtık ve yüksek ölçeklenebilir yapıda çalışabilir. Alternatiflerine göre çok az kaynak kullanarak çalışır. RestfullAPI desteği vardır.
ElasticSearch Kavramları
Indice: ElasticSearch aramaları “Indice” olarak adlandırılan indeks dosyaları üzerinden gerçekleştirilir.
Gelin Kibana arayüzünden Dev Tools alanına gidelim. Bu ekranda sorgu yazabilir, index oluşturabilir, arayabiliriz. Temel bir kaç komutu inceleyelim.
GET /_cat/nodes?help % Elasticsearchteki yardım havuzuna gidebileceğimiz komut.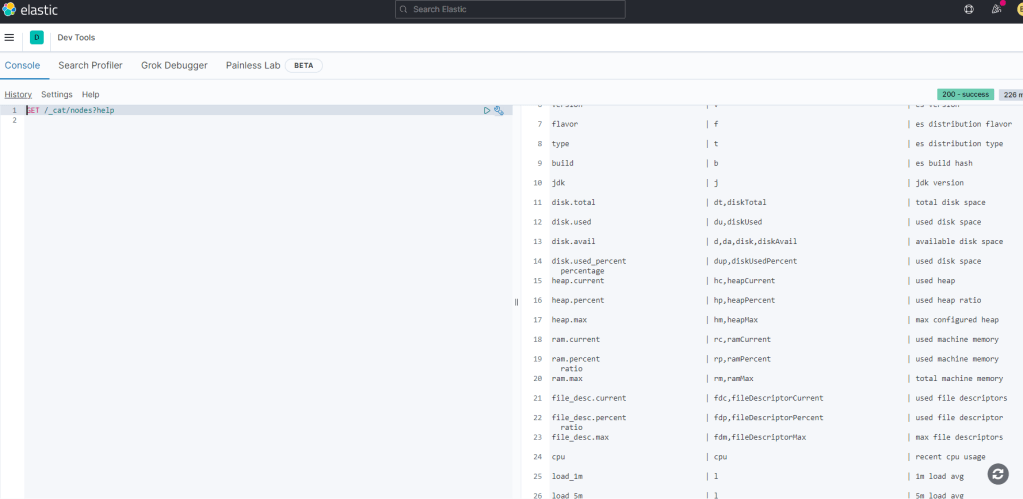
PUT % İndex oluşturur.
GET % Oluşturulan indexi görür.
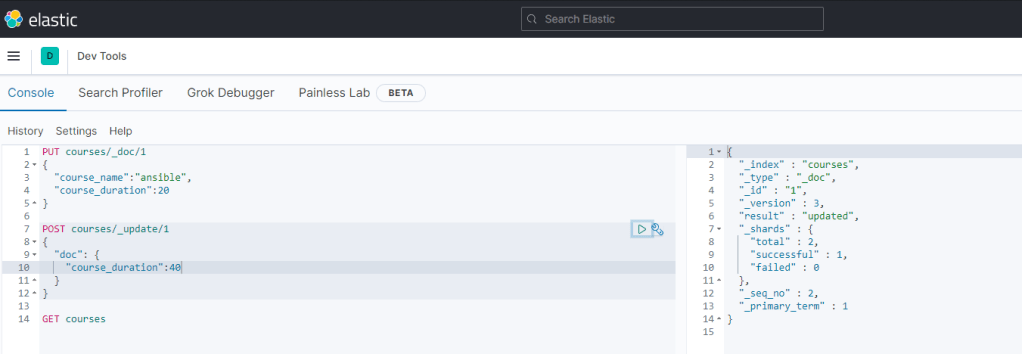
POST % İndex'i update eder.
DELETE % İndexi siler.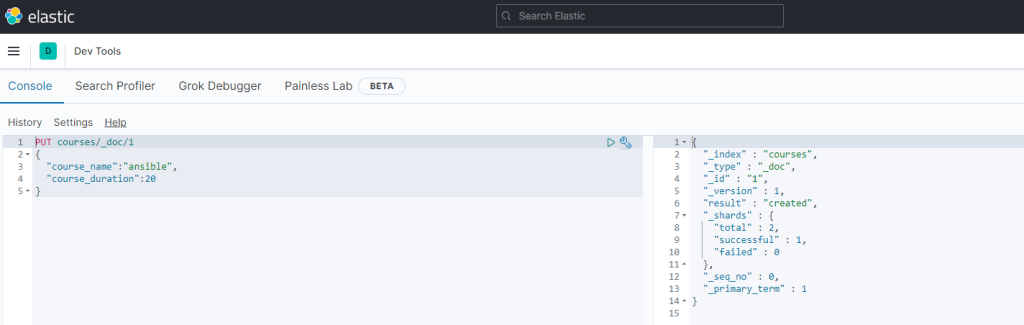
Mapping: İndekslenen verilerin hangi veri tipinde olduğunun tanımlandığı işleme denir. Mapping’i aşağıdaki örnekteki gibi kullanabiliriz.
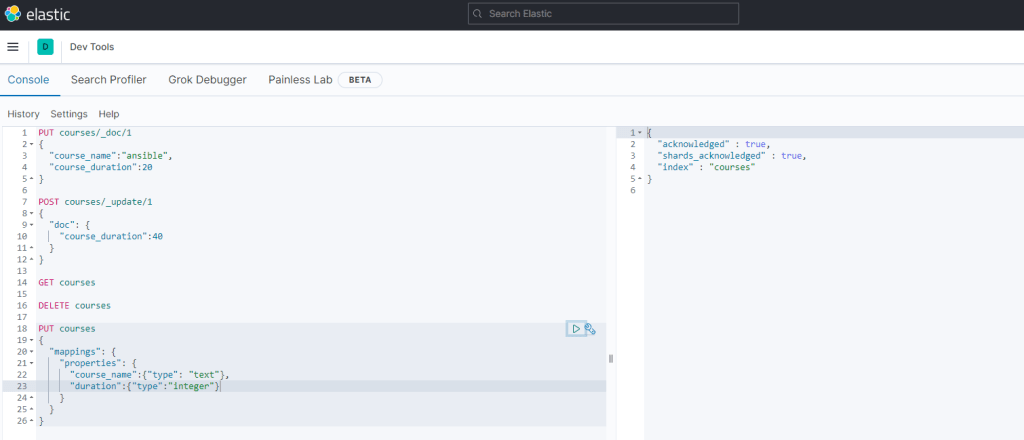
Bulk : Elasticsearch üzerinde indeksleme işlemi birkaç farklı yöntem ile yapılabilmektedir. Yukarıda yaptığımız gibi tek tek index oluşturubileceğimiz gibi birden fazla indexi tek seferde de girebiliriz. İşte bu indexleme türü Bulk İndexleme olarak adlandırılır.
NOT | Index ve Create Farkı: Index ve create ikisi de temelde insert işlemi yaparken aralarında bir fark vardır. Index ile yollanan istekte aynı Id’ye sahip başka bir document olsa bile onu replace eder. Create ise revize işlemi yapamaz, hata verir.
Request:
POST courses/_bulk
{"index": {"_id": "1"}}
{"course_name":"ansible", "duration": 20}
{"index": {"_id": "2"}}
{"course_name":"linux", "duration": 50}
{"index": {"_id": "3"}}
{"course_name":"openshift", "duration": 42}
{"index": {"_id": "4"}}
{"course_name":"PYTHON", "duration": 36}
{"create": {"_id": "5"}}
{"course_name":"vSAN", "duration": 30}Analyzer: Elasticsearch’e yolladığınız dökümanlardan maksimum performans ve amaca hizmet edebilen bir search yapısı oluşturabilmek için bazı işlemler yapılması gerekir. Bu işlemlerin bütünü Analysis, işlemi yapan kısım ise Analyzer olarak adlandırılır. Yapılan analiz işlemleri aşağıdaki gibidir:
1. Karakter filtreleme ( Birebir girmiş olduğumuz metnin çıktısını almaktayız.)
2. Tokenizer ( Parçalara ayırarak çıktı verir. Soru işereti, ünlem, tire şeklinde karakterlerin dönüşünü yapmaz. )
3. Token filtreleme ( Tokenizer’dan farkı büyük harf küçük harf duyarlılığıdır. )
Query: Elasticsearch’te sorgu yapmak için kullanılır.
Query Tipleri:
- URI Query: hızlı sorgu işlemlerinde kullanılır, karmaşık sorgular için uygun değildir.
- DSL Query: okunması kolaydır, karmaşık sorgular için uygundur.
- Leaf Query: Belirli bir alanla ilgili arama yapılmasını sağlar.
- Compound Query: Birden fazla alanla ilgili arama yapılmasını sağlar.
Request: % URI query example
GET courses/_search?q=duration:42DSL Query’de search için birtakım keywordler bulunmaktadır. Bunlardan bazıları şunlardır:
→ match: Birebir uyumlu olan alanı getirir.
Yukarıda bulk ile oluşturduğumuz index dizisinden dsl query ile sorgu yapmak istersek:
Request: % DSL query + match example
GET courses/_search
{
"query": {
"match": {
"course_name": "vSAN"
}
}
}→ term: Bu metod tamamen küçük harfleri baz alır. Siz büyük harflerle yazsanız bile arka planda küçük harflere çevirerek arama yapar.
Request: % DSL query + term example
GET courses/_search
{
"query": {
"term": {
"course_name":"python"
}
}
}→ range: Bu metod belirtilen aralıklardaki alanları getirir.
Range ile kullanılabilecek operatörler şunlardır:
-gte: greater than equal to
-gt: greater than
-lte: less than equal to
-lt: less than
Request: % range example
GET courses/_search
{
"query": {
"range": {
"duration": {
"gte":20,
"lte":45
}
}
}
}→ Wilcard ve Prefix ile Query İşlemleri: Wilcard ve prefix arasındaki fark tamamen performans üzerinedir. Prefix’te ayarları belirtiyoruz, ona göre performansı yüksek tutuyor.
Request: % wildcard example
GET courses/_search
{
"query": {
"wildcard": {
"course_name": {
"value": "ans?ble"
}
}
}Wilcard ile yaptığımız sorgu işlemini prefix ile yapalım. Aşağıdaki örnekte önce mapping işlemi yapıyorum ve ayarları belirtiyorum. İkinci request işleminde kitap ismini belirterek indexi update ediyorum. Son olarak üçüncü request’te prefix metoduyla indexte arama yapacağım. “min” ve “max” değerine göre sorgu yapacağı için value kısmında en az 2 harf belirtmemiz gerekir. 1 harf belirtirseniz hata alacaktır. Deneyebilirsiniz 🙂
% prefix example
Request1:
PUT test
{
"mapping": {
"properties": {
"book": {
"type": "test",
"index_prefix": {
"min_chars":2,
"max_chars":5
}
}
}
}
}
-----------------------------------------------------------------------------------
Request2:
POST test/_doc/1
{
"book":"satranc"
}
-----------------------------------------------------------------------------------
Request3:
GET test/_search
{
"query": {
"prefix": {
"book": {
"value": "sa"
}
}
}
}→ Sorting: Sıralama işlemlerinde kullanılır. SQL’den de bildiğimiz ASC ve DESC keywordlerini burada da kullanacağız. ASC ile indexleri artan sıraya göre, DESC ile ise tersten sıralama işlemi yapabiliriz. Basit bir sort işlemi aşağıdaki gibi olacaktır.
Request: % sorting example
GET courses/_search
{
"sort": [
{
"duration": {
"order": "desc"
}
}
]
}Answer: % sorting example
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"course_name" : "linux",
"duration" : 50
},
"sort" : [
50
]
},
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"course_name" : "openshift",
"duration" : 42
},
"sort" : [
42
]
},
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "4",
"_score" : null,
"_source" : {
"course_name" : "PYTHON",
"duration" : 36
},
"sort" : [
36
]
},
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "5",
"_score" : null,
"_source" : {
"course_name" : "vSAN",
"duration" : 30
},
"sort" : [
30
]
},
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"course_name" : "ansible",
"duration" : 20
},
"sort" : [
20
]
}
]
}
}→ Pagination: Çektiğimiz verileri sayfa sayfa listelemeye yarar. “from” ve “size” komutları ile bu işlem yapılabilmektedir. Yani daha önce courses olarak oluşturduğumuz veriden 2.indexten başlayıp 5 tanesini bize getir demek istersek aşağıdaki şekilde işlemi yapmamız gerekir.
Request: % pagination example
GET courses/_search
{
"from": 1
, "size": 5
}→ Fuzzy Query: Özelliği text alanı içerisindeki bir harfin yer değişimini veya eksikliğini otomatik olarak tamamlamasıdır.
Request: % fuzzy query example
GET courses/_search
{
"query": {
"fuzzy": {
"course_name": "ansi"
}
}
}Bir başka örnek ile inceleyecek olursak,;
Kaç karakteri tamamlayacağını fuzziness komutuyla belirtebiliriz. Bunu dilersek auto olarak da seçip otomatik tamamlamasını söyleyebiliriz.
Request: % fuzzy query example 2
GET courses/_search
{
"query": {
"fuzzy": {
"course_name": {
"value": "lin", "fuzziness": 2
}
}
}
}Answer: % fuzzy query example 2
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.46209806,
"hits" : [
{
"_index" : "courses",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.46209806,
"_source" : {
"course_name" : "linux",
"duration" : 50
}
}
]
}
}
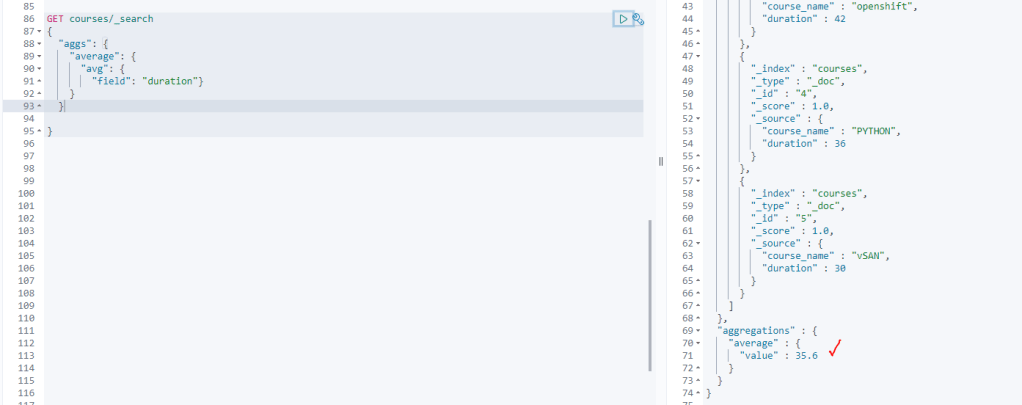
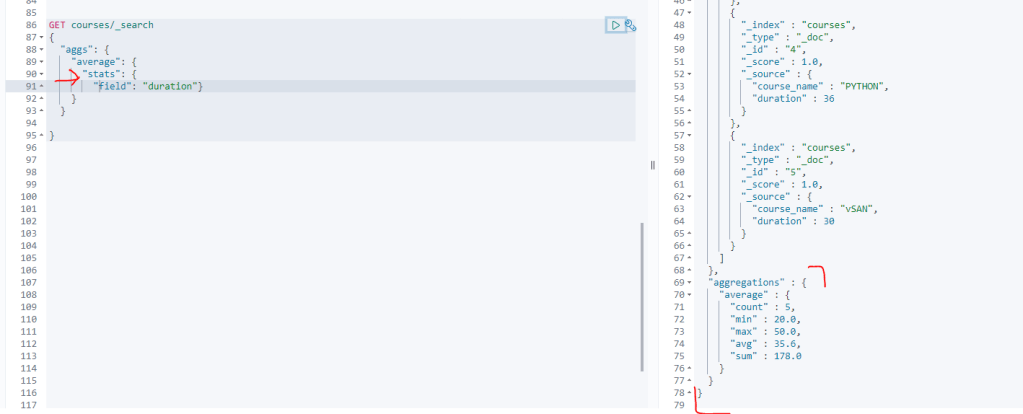
Aggregations: Verisetimizde ortalama, min, max ve toplama işlemlerini yapmaya imkan tanıyan arama şeklidir. Aşağıdaki görüntüdeki gibi eğitim sürelerinin ortalamalarını alabiliriz. Aynı şekilde “avg” yerine bu komutları ekleyerek diğer işlemleri de yaptırabilirsiniz.
-Avg: Ortalamasını alır.
-Min: Minimum değeri alır.
-Max: Maksimum değeri alır.
-Sum: Toplam değerini getirir.
-Stats: Avg, min, maxi sum bilgilerinin tamamını verir.
Yazı serisinin devamında Lostash ve Kibana üzerine konuşacağız. Bugünlük müessesemizden bu kadar : )
Elasticsearch ile alakalı takip ettiğim eğitim serilerinin de linklerini buraya bırakıyorum.
https://www.elastic.co/training/elasticsearch-engineer
https://www.youtube.com/playlist?list=PLFzFX4nf_25zFjWqEjReoS07U4ic0VuZO
Kolaylıklar 🐸
