
Merhaba bugün sizlerle Elasticsearch ile Anomaly tespiti üzerine konuşacağız. Anomali tespit temelde bir makine öğrenim modelidir. Makine öğrenimi anormallik algılama özellikleri, verilerinizde normal davranışın doğru temellerini oluşturarak zaman serisi verilerinin analizini otomatikleştirir. Bu taban çizgileri daha sonra anormal olayları veya kalıpları belirlemenizi sağlar. Anomali tespiti için zamana bağlı veriler gerekir.
Peki, Elasticsearch ile Anomali Tespiti nasıl sağlanır?
Veriler, analiz için Elasticsearch’ten alınır ve anormallik sonuçları Kibana panolarında görüntülenir. Bu yöntemde bir olasılık modeli oluşturulur ve meydana gelen olağandışı olayları tanımlamak için sürekli olarak data toplar.
Anomali Tespiti için öncelikle anomali job’ı oluşturulmalıdır. Kibana arayüzünde“Anomaly Detection” sekmesine gidilir ve ardından “Create Job” butonuna basılır. Açılan ekranda anomali tespiti gerçekleştirmek için gerekli ndex pattern’i seçilir.
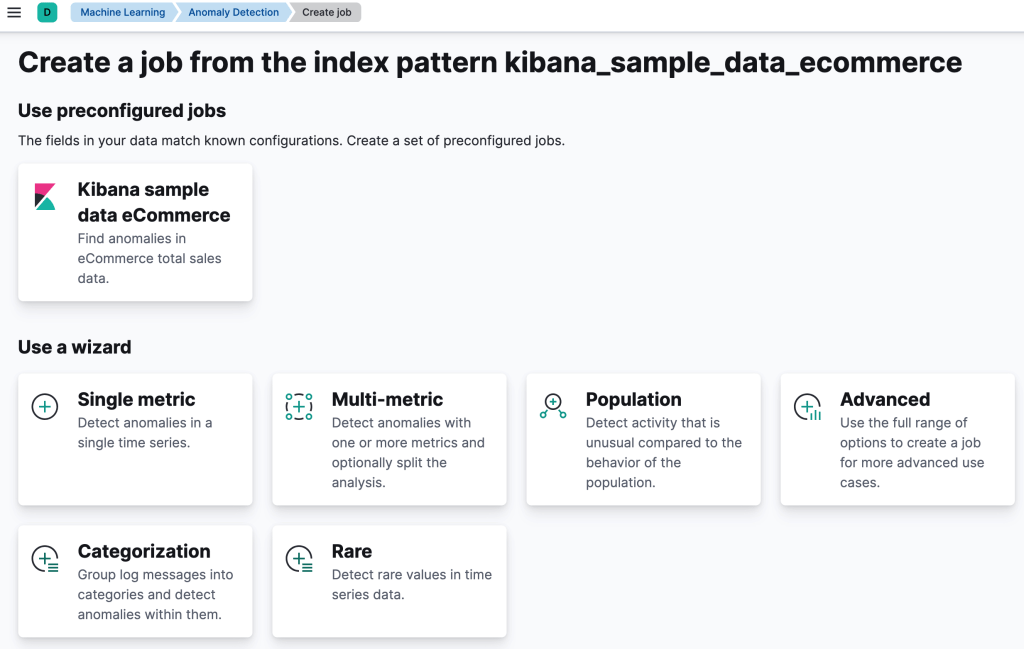
Job oluştururken yukarıdaki görselde de gözüktüğü gibi tercih edilebilecek bazı sihirbazlar bulunmaktadır. Gelin bu sihirbazları biraz daha detaylı inceleyelim.
Single Metric, tek bir dedektöre sahip basit işler oluşturur. Bir dedektör, verilerinizdeki belirli alanlara analitik bir işlev uygular. Single metric sihirbazu, dedektör sayısını sınırlamaya ek olarak, daha gelişmiş yapılandırma seçeneklerinin çoğunu atlar.
Multi-metric, birden fazla algılayıcıya sahip olabilen ve aynı verilere karşı birden çok işi çalıştırmaktan daha verimli olan işler oluşturur.
Population, popülasyonun davranışına kıyasla olağandışı etkinliği algılayan işler oluşturur.
Categorization, günlük mesajlarını kategoriler halinde gruplandıran ve içlerindeki anormallikleri algılamak için count veya işlevlerini kullanan işler oluşturur
Advanced, birden çok detektöre sahip olabilen işler oluşturur ve tüm iş ayarlarını yapılandırmanıza olanak tanır.
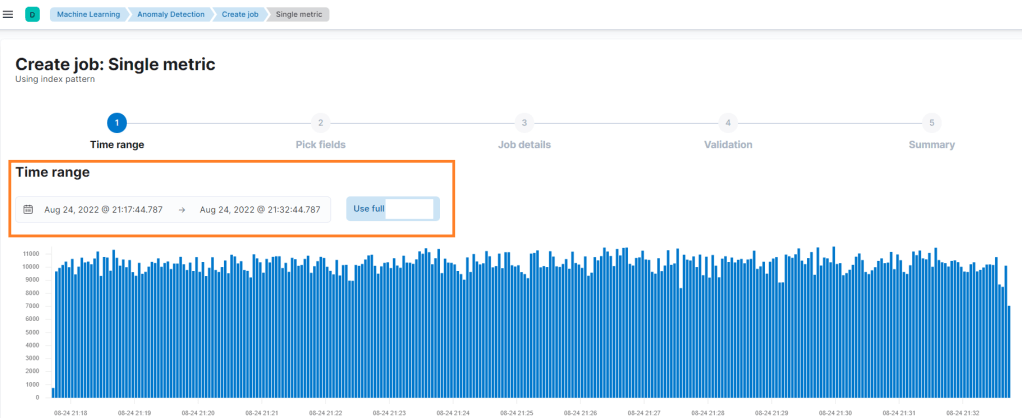
Anomali tespiti gerçekleştirilecek ortama ait metrikleri “time range” kısmından sınırlandırabilirsiniz ya da tüm metrikleri kullanabilirsiniz. Time range size tercih ettiğiniz zaman aralığında anomali tespiti yapabilmenizi sağlar.
Bir sonraki aşamada Pick Fields adımı karşınıza gelecek. Burası average, min ve max gibi fonksiyonları içerir.

Gelin şimdi de anomali tespiti yaparken seçebileceğiniz fonksiyonları inceleyelim.
- Count: Bucket’daki genel olay sayısının normalden daha yüksek veya daha düşük olduğu zaman dilimlerini tanımlar.
- High_count: Bucket’daki olay sayısı olağandışı derecede yüksek olduğunda anormallikleri algılar. Diğer kullanıcılara kıyasla alışılmadık derecede yüksek sayıda hata kodu oluşturan kullanıcıları algılar.
- Low_count: Bucket’daki olay sayısı olağandışı derecede düşük olduğunda anormallikleri algılar. Bu işlevi anormallik algılama işinizde bir dedektörde kullandığınızda, her bir durum kodu için olay oranını modeller ve bir durum kodunun geçmiş davranışına kıyasla olağandışı derecede düşük bir sayıya sahip olduğunu algılar.
- Mean: Bir değerin aritmetik ortalamasındaki anormallikleri algılar. Ortalama değer, her bir kova için hesaplanır.
- High_mean: Alışılmadık derecede yüksek ortalama değerleri izlemek istiyorsanız bu işlevi kullanın.
- Low_mean: Alışılmadık derecede düşük ortalama değerlerle ilgileniyorsanız, bu işlevi kullanın.
- Sum: Bir bucket alan toplamının anormal olduğu verileri algılar. Bu sum işlevi anormallik algılama işinizde bir dedektörde kullanırsanız, her bir maliyet merkezi için çalışan başına toplam giderleri modeller. Her zaman bölümü için, bir çalışanın harcamalarının diğer çalışanlara kıyasla bir maliyet merkezi için olağandışı olup olmadığını tespit eder.
- High_sum: Bu işlevi anormallik algılama işinizde bir dedektörde kullanırsanız, total modelini oluşturur. Diğerlerine kıyasla alışılmadık derecede yüksek hacimlerin aktarıldığını algılar.
- Low_sum: Bu işlevi anormallik algılama işinizde bir dedektörde kullanırsanız, total modelini oluşturur. Diğerlerine kıyasla alışılmadık derecede düşük hacimlerin aktarıldığını algılar.
- Median: Bir değerin istatistiksel medyanındaki anormallikleri algılar. Medyan değer, her bir kova için hesaplanır.
- High_median: Alışılmadık derecede yüksek ortalama değerleri izlemek istiyorsanız bu işlevi kullanın.
- Low_median: Alışılmadık derecede düşük ortalama değerlerle ilgileniyorsanız, bu işlevi kullanın.
- Min: Bir değerin aritmetik minimumundaki anormallikleri algılar. Her kova için minimum değer hesaplanır. Bu işlevi anormallik algılama işinizde bir dedektörde kullanırsanız, en küçük işlemin daha önce gözlemlenenden daha düşük olduğu yeri algılar.
- Max: Bir değerin aritmetik maksimum değerindeki anormallikleri algılar. Her kova için maksimum değer hesaplanır.
- Distinct count: Bir alandaki farklı değerlerin sayısının olağandışı olduğu anormallikleri algılar.
Pick fields alanında seçtiğiniz fonsiyona göre ekrandaki gibi bir grafik sizi karşılıyor. Ayrıca “bucket span” ve “sparse data” isimli 2 yeni terime de hoşgeldin dememiz gerekiyor 🙂
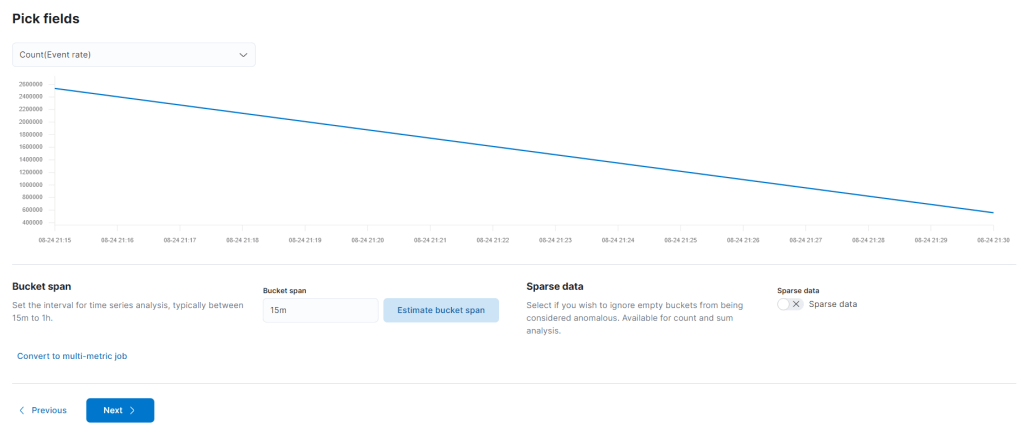
Bucket span, Makine öğrenimi özellikleri, zaman serilerini işlenmek üzere gruplara bölmek için kullanılır. Bir anormallik algılama işi için yapılandırma bilgilerinin bir parçasıdır. Verileri özetlemek ve modellemek için kullanılan zaman aralığını tanımlar. Bu genellikle 5 dakika ile 1 saat arasındadır ve veri özelliklerinize bağlıdır. Bucket span’ı ayarladığınızda, analiz etmek istediğiniz ayrıntı düzeyini, giriş verilerinin sıklığını, anormalliklerin tipik süresini ve uyarının gerekli olduğu sıklığı dikkate alın.
Sparse Data, verisetindeki boş metriklerin anormal olarak değerlendirilmesi istenirse seçilir.
Bu alanları da yapınıza uygun tercih ettikten sonrası bir sonraki aşama için next diyoruz. Burada Job ID ve groups sekmeleri karşımıza geliyor. Job ID, Job’a verilecek isimdir. Groups, Job etiketleme için kullanılır. Örneğin Ceph clusterınız için bir anomali tespiti oluşturuyorsanız burada Ceph olarak bir tag yani group oluşturabilirsiniz. Job description, Job hakkında açıklama girilmek istenirse doldurulur.
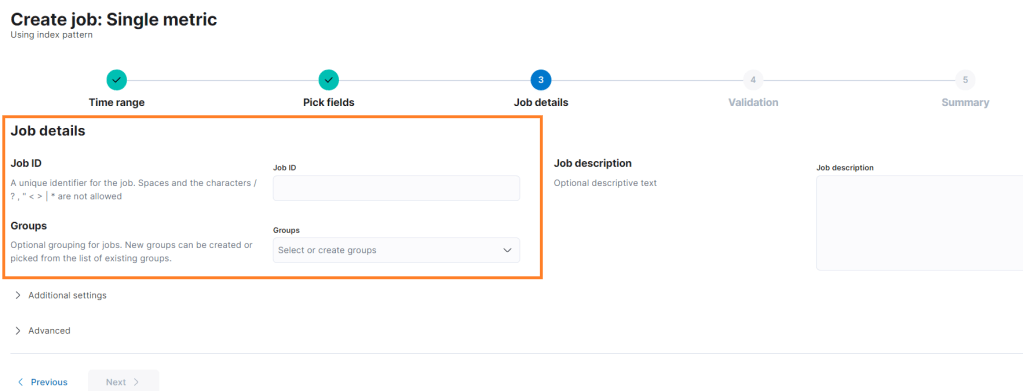
Biz sonraki adımda yapılanların genel bir özeti, yani köprüden önceki son çıkış tabı yer alır 🙂 Her şey tamam ise “Create Job” ile job oluşturulur.

Tebrikler , buraya kadar takip ettiysen bir anomali job’ını başarıyla oluşturdun demektir. Oluşan jobların tamamını anomalyt detection sekmesinden görüntüleyebilirsin.
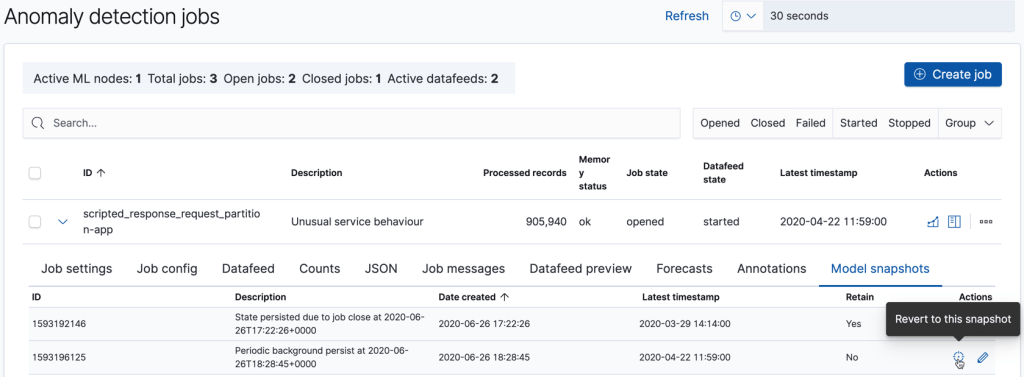
Anomali Sonuçlarını nasıl inceleriz?
Kibana’da anormallik algılama çalışmalarından elde edilen sonuçları incelemek için iki araç vardır: Anomaly Explorer
Single Metric Viewer.
Makine öğrenimi sonuçlarınızı görüntülediğinizde, her paketin bir anormallik puanı olacaktır. Bu puan, tüm kayıt sonuçlarının birleşik anormalliğinin istatistiksel olarak toplu ve normalleştirilmiş bir görünümüdür.
Makine öğrenimi sonuçlarınızı gözden geçirdiğinizde, son anomali puanının ne kadar güçlü bir şekilde etkilendiğini gösteren bir multi_bucket_impact özelliği vardır. Kibana’da, orta veya yüksek çoklu etkiye sahip anormallikler, Anomaly Explorer ve Single Metric Viewer’da nokta yerine bir çarpı işaretiyle gösterilir.
Aşağıdaki örnekte bazı anormalliklerin, beklenen değerlerin sınırlarını temsil eden gölgeli mavi alan içinde kaldığını görebilirsiniz. Burada turuncu alanda bir anormallik olduğu gözlenebilir. Kök neden tespiti için ilgili kayıtları inceleyerek daha fazla araştırma yapabilirsiniz.

Bir diğer örneğe bakacak olursak, aşağıdaki görselde kırmızı ile belirtilan alanda normal olmayan bir metrik toplanmıştır.
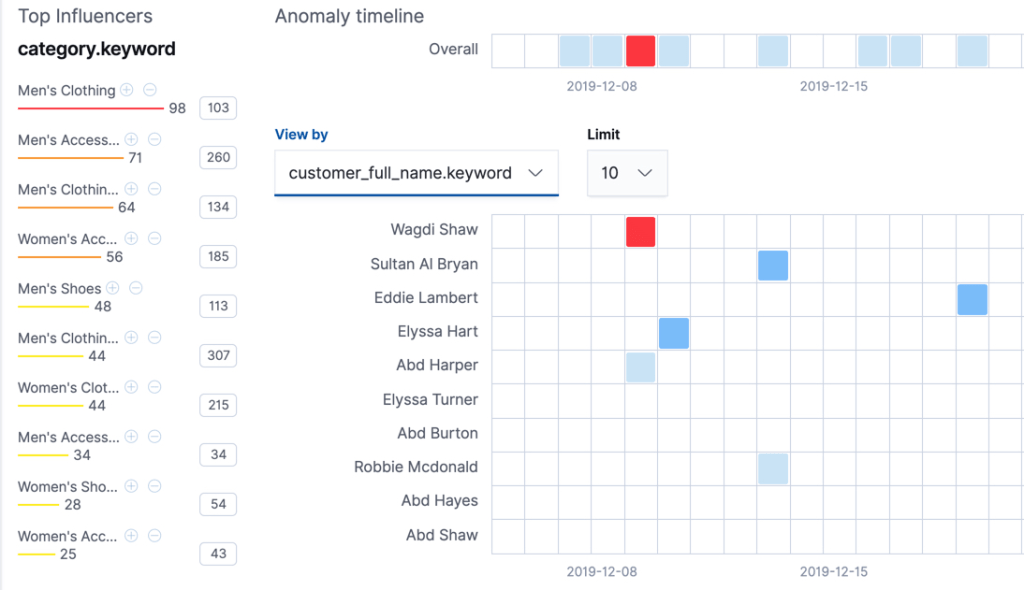
Burada renk skalası bize normalden anormale gidişattaki yoğunluğu belirtir. Yani mavi rengi normal, kırmızı en en en anormal olarak kabul ederiz.

Özetlersek, bu yazıda anomali tespitinden, elasticsearch ile nasıl anomali job’ı oluşturduğumuzdan ve sonuçlarını nasıl inceleyeceğimizden bahsetmiş olduk.
Gelecek yazılarda görüşmek üzere, yağmurlu bir yaz akşamından esen kalın 🐸

DİPNOT: Yağmur deyince akla gelen şemsiye, şemsiye ile anomaly detection uyumluluğunun sağlanması ve şemsiyenin sarı olması lise yıllarımda çok severek izlediğim bir diziyi hatırlattı bana. Meraklısı için bir dizi tavsiyesi gelsin öyleyse: Love Rain 🌂
