

Merhaba, bu yazı serisinde sizler ile “Red Hat Ceph Storage 5.0 CL260” eğitimini referans alarak tuttuğum notlarımı paylaşıyor olacağım.
Öncelikle kısaca geleneksel depolama çözümleri ile yazılım tabanlı depolama çözümlerine (SDS) bakaraK SDS ile kazandığımız ayrıcalıkları listeleyelim.
Geleneksel Depolama Çözümleri:
-Donanım ve yazılım birlikte verilen çözümlerdir.
-Bir veri merkezi üzerine konumlandırılır.
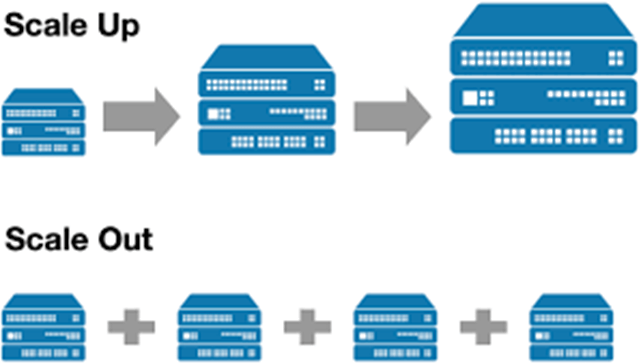
-Scale-up ölçeklendirilir.
-Storage admin ihtiyacı vardır.
Yazılım Tabanlı Depolama Çözümleri:
-Yazılım tabanlıdır. Donanım bağımsızdır.
-On-premise, public ya da hibrit cloudda çalışabilir.
-Scale-out ölçeklendirilir.
-Self-servis kullanılabilir.
Yazılım tabanlı çözümler yukarıda belirttiğim gibi donanım bağımsızdır. Bu da size hardware seçim avantajı sağlayacaktır. Bu donanımların ciddi paralar olduğunu düşünürsek burada maliyetten de tasarruf imkanı sağlar diyebiliriz. Geleneksel çözümler de ölçeklendirilebilir fakat belli limitasyonlara sahiptir. Alan arttırımı ürünün kapasitesin bağlıdır. Sınıra ulaşıldığında yeni bir depolama alanı satın alınması gerekecektir. Alan arttırımı ürünün kapasitesin bağlıdır. Sınıra ulaşıldığında yeni bir depolama alanı satın alınması gerekecektir. Yazılım tabanlı çözümler ise esnektir, Scale out olarak mevcut yapıdan bağımsız şekilde arttırım yapabilir.
Gelelim ana konumuz Ceph‘e.
Ceph, yazılım tanımlı, birleşik depolama çözümleri sunan açık kaynaklı bir projedir. Openshift, openstack ortamlarının storage ihtiyacını karşılamak amacıyla yaygın kullanılır. Wikipedia’dan historye bakacak olursak; bu projenin mimarı Sage Weil ‘dir. Sage Weil, Los Angeles merkezli hosting şirketi DreamHost’un kurucu ortağı, WebRing’in mimarı ve Inktank’ın kurucusu ve CTO’suymuş. Şimdi de Ceph projesinin baş mimarı olarak Red Hat için çalıştığını öğrendim.
Ceph, mükemmel performans, güvenilirlik ve ölçeklenebilirlik sağlamak üzere tasarlanmıştır. Ceph’e giriş amacıyla hazırladığım CEPH 101 paylaşımımda Ceph’in faydalarına ve mimari bileşenlerine değinmiştim. Bu yazının devamını okumadan önce CEPH 101 yazımı da okumanızı tavsiye ederim.
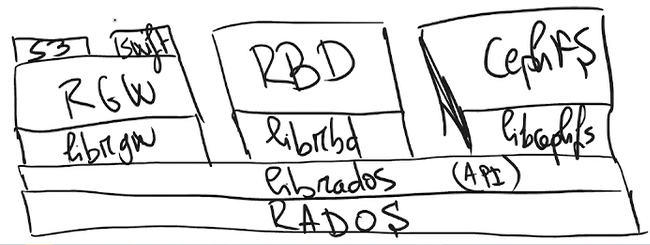
Çok kısaca genel yapıya baktığımızda RADOS altyapıda storage yazma işleminden sorumludur. RGW(Rados Gateway), RBD(Rados Block Device), CephFS(File System) ise bizim için clientlar ile haberleşmeyi sağlayan metodlardır.
Ceph Storage Backend Daemons
Red Hat Ceph Storage clusterı aşağıdaki daemonlara sahiptir:
1.Monitor (MON’s) :
Cluster durumunun haritalarını korur. Dçğer daemonların koordinali çalışmasına yardım eder.
2.Object Storage Devices (OSD’s) :
Verileri depolar ve veri çoğaltma, kurtarma ve yeniden dengeleme rollerini üstlenir.
2.1. Crush Map
Ünlü bir düşünür der ki “where to find the data , where to put the data ?” . Ünlü de olmayabilir 🙂 Ama birileri bu soruya kafa yormus ve bir algoritma geliştirmiş: Crush Algoritması.
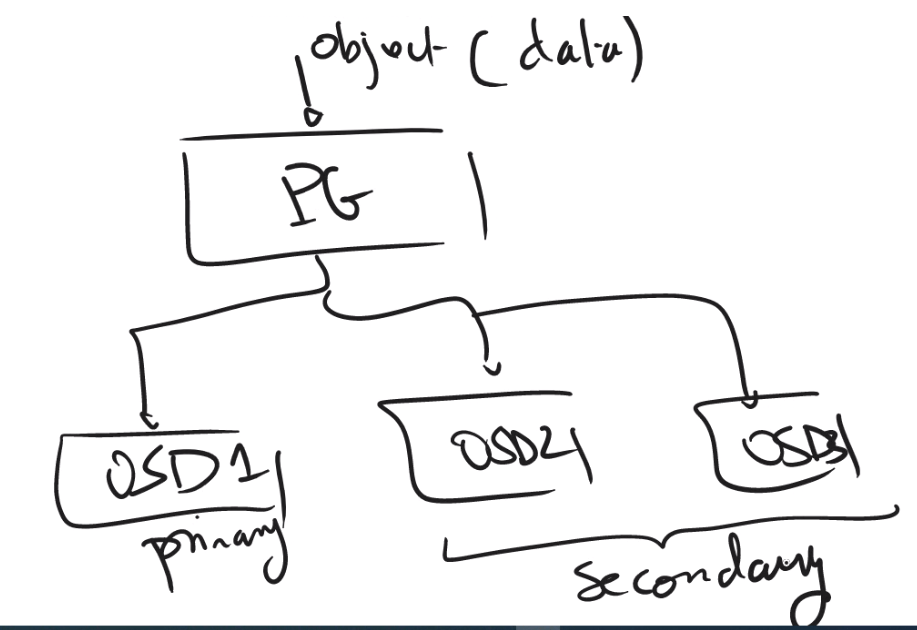
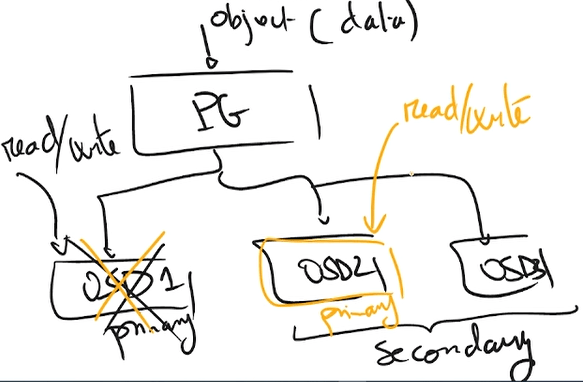
CRUSH, her nesneyi tek bir karma kova (single hash bucket) olan yerleşim grubuna (PG) atar. PG’ler, nesneler (uygulama katmanı) ve OSD’ler (fiziksel katman) arasında bir soyutlama katmanıdır. CRUSH, nesneleri PG’ler arasında dağıtmak için sözde rastgele bir yerleştirme algoritması kullanır ve PG’lerin OSD’lere eşlenmesini belirlemek için kurallar kullanır. Primary OSD’ye read/write işlemleri yapılır. Arıza durumunda ise Ceph, PG’leri farklı fiziksel cihazlara ( Secondary OSDs) yeniden eşler ve içeriklerini yapılandırılmış veri koruma kurallarına uyacak şekilde senkronize eder.
Normal şartlar altında
Arıza durumunda
3.Managers (MGR’s) :
Çalışma zamanı ölçümlerini izler ve tarayıcı tabanlı bir dashboard ve REST API aracılığıyla cluster bilgilerini gösterir.
4.Metadata Servers (MDS’s) :
POSIX komutlarını verimli bir şekilde çalıştırabilmeleri için CephFS’nin kullandığı meta verileri depolar. Nesne depolama ve blok depolama için clusterda MDS’e ihtiyaç yoktur.
Cluster Map
5 harita bulunuyor. Ceph istemcileri ve OSD’ler, cluster topolojisi hakkında bilgi gerektirdiğinden bu haritaları kullanır. Aşağıda bu haritaları ve komutlarını belirttim.
--monitormap: contains cluster id (fsid)
$ ceph mon dump
--osdmap: pgs and pool id
$ ceph osd dump
--pgmap: pool ratio , more details about the pgs, pgs data usage , etc.
$ ceph pg dump
--crushmap: list of storage devices, getting this map
$ ceph crush dump
--mdsmap: some information about the daemon
$ ceph fs dumpData Protection
Poolları oluştururken yerleşim gruplarının (placement groups) sayısını ve replika sayısını, “CRUSH” kuralını belirtmemiz gerekmektedir. İki tür pool bulunur. Birincisi “replicated pools”, diğeri ise “erasure coded pools”.
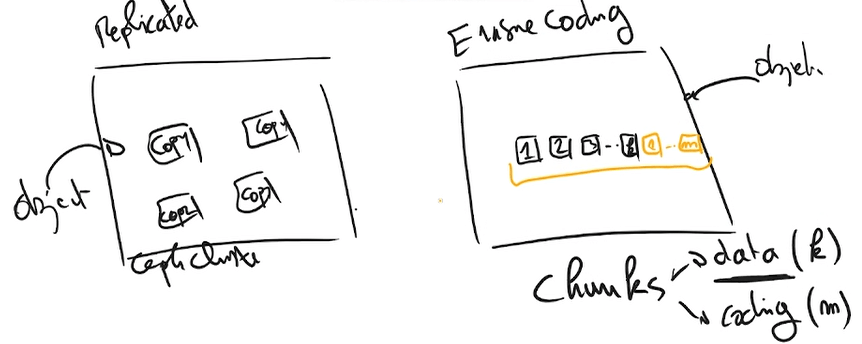
Replika tipinde veri bir kaç kopya halinde tutularak veri güvenilirliği ve dayanıklılığı sağlanırken, EC ise veri hata bölgelerini gözetecek şekilde belli parçalara (chunk) bölerek dağıtık şekilde tutulur. Burada veri bütünlüğünü sağlamak amacıyla ekstra parçalar(4 e bölüyorsa mesela +2 tane daha mesela metadata kullanıyor) kontrol parçacıkları ekleniyor. Her bir chunk belirlenen oranlarda belirlenen nodelara dağıtılıyor. Bu şekilde daha az yer kaplıyor ama daha fazla cpu tüketiyor. Eğer bütçeniz kısıtlı ise EC kullanmak bir tercih olabilir.
Replikasyon yönteminde bir kopya asıl hedefe yazıldıktan sonra diğer kopyalar ikinci bir ağ (cluster network) üzerinden kopyalanmaktadır. Yazma işlemi sırasında replika sayısı kadar yazma yapılmadan işlem tamamlanmayacağı için yazma işlemi uzasa da, okuma sırasında farklı kopyalardan farklı bölümler okunarak işlem hızlanacaktır. Elbette veriyi bir kaç kopya halinde tutmak daha maliyetli olacak ancak sistemin hata toleransı bu durumda artar ve okuma performansı yükselecektir.
Replika sayısı arttıkça sistem üzerinde bir şekilde devre dışı kalan disk veya sunucu olması halinde performans düşüşü kaynaklı yaşanan etki azalır diyebiliriz. Ayrıca cluster üzerinde herhangi bir durumda (disk değişimi, sunucu arızası v.b.) başlayacak veri kurtarma (recovery) işlemi birden fazla kopyadan okunarak EC’ye göre oldukça hızlı bir biçimde yapılacaktır.
Toparlayacak olursak, bütçe çerçevesinde farklı katmanlar (object, block, filesystem) için replika veya EC kullanılabilir. Bu seçimi yaparken sistemdeki okuma-yazma oranı dikkate alınmalıdır. Kritik veriler için replika yöntemi önerilirken daha çok arşiv amaçlı ihtiyaçlarda EC önerilmektedir. Yani veriyi saklayıp çok sık erişmeyeceğiniz durumlarda (cold storage) EC, sürekli kullandığınız durumlarda replika kullanmak daha mantıklı olacaktır. Genel kabül replikasyon yönteminde en az 3 replika tutmak şeklindedir. Ancak bütçe kısıtı gibi durumlarda 2 replika da kullanılabilir. Seçilen yöntem doğrultusunda donanım seçimi yapılmalıdır.
Bugünlük bana ayrılan sürenin sonuna geldik, Yazı serisinin gelecek paylaşımında Ceph Storage Cluster’ın nasıl konumlandırıldığından ve konfigürasyon süreçlerinden bahsediyor olacağım.
Geceye bu sıralar müptelası olduğum şarkıyı hediye ederek şimdilik veda ediyorum 🐸

“Ceph Storage Notlarım {1/5}” için 2 yorum