

Selamlar dostlar,
Bugün sizlere TurkNet’te AWS S3’ten Huawei OBS’ye gerçekleştirdiğimiz migration işleminden bahsetmek istiyorum.
İşletmeler bazen farklı özelliklerden yararlanmak, maliyetleri optimize etmek veya düzenleyici gereksinimleri karşılamak için bu tarz dönüşümlere ihtiyaç duyabiliyor. Biz de bazı datalarımızı AWS S3’ten Huawei Object Storage Service’e (OBS) taşıyarak her iki platformdan da yararlanmak istiyoruz. Eğer sizin de AWS S3’ten başka bir ortama çoklu data taşıma işlemine ihtiyacınız var ise bu yazı ile bu işlemi nasıl daha hzılı otomatize ederek gerçekleştirebileceğinize bakabilirsiniz.
Öncelikle biraz AWS S3 ve Huawei OBS’den kısaca bahsetmek istiyorum.
AWS S3
Amazon Simple Storage Service (S3), endüstri lideri ölçeklenebilirlik, veri erişilebilirliği, güvenlik ve performans sunan yaygın olarak kullanılan bir nesne depolama hizmetidir. AWS S3, web üzerindeki herhangi bir yerden herhangi bir miktarda veri depolamak ve almak için tasarlanmıştır. Arşivlenmiş veriler için AWS, düşük maliyetli depolama çözümleri sunan S3 Glacier ve S3 Glacier Deep Archive hizmetlerini sunar.
Huawei OBS
Huawei Object Storage Service (OBS), güvenli, güvenilir ve maliyet etkin depolama çözümleri sunan bir bulut depolama hizmetidir. OBS, büyük ölçekli veri depolamayı destekler, diğer Huawei Cloud hizmetleri ile sorunsuz bir şekilde entegre olur ve güçlü veri koruma özellikleri sunar. Huawei’in bu yıl itibariyle Türkiye zone ununu da hizmete açması Huawei’nin Türkiye pazarında yerinin de önemini arttırmıştır.
S3 Migration from AWS to Huawei
Şimdi asıl konumuz migration işlemi üzerine konuşmaya başlayabiliriz. Burada S3 teki taşınacak objelerin storage classını kontrol ederek başlamamız gerekiyor. Çünkü eğer S3 Glacier veya S3 Glacier Deep Archive depolama sınıfında objeleriniz var ise doğrudan verilere erişmeniz mümkün değil. Öncelikle restore işlemi yapılarak objelerin erişilebilir olmasını sağlamamız gerekiyor. Amazon S3 ve veri depolama sınıfları ile ilgili daha detaylı bilgi için Ajandada Bugün: “Amazon s3” yazımı okuyabilirsiniz.
Restore with Batch Operations
👉🏻S3 Glacier Deep Archive depolama sınıfındaki bir objeyi taşımadan önce, veriyi geri çağırmanız (restore) gerekir. Bu işlem, veriyi daha erişilebilir bir duruma getirir. Restore işlemi saatler ila günler arasında sürebilir. S3 Glacier Deep Archive için bu süre genellikle 12 saatten 48 saate kadar uzadığını söyleyebilirim.
👉🏻Restore işlemi, S3 Glacier Deep Archive’deki objenin geçici bir kopyasını S3 Standard, S3 Standard-IA gibi daha erişilebilir bir depolama sınıfında oluşturur. Bu geçici kopya belirli bir süre (genellikle 1-15 gün arasında) boyunca erişilebilir olur. Bu süreyi siz ihtiyacınıza göre belirleyebiliyorsunuz. Tabi ki ücreti mükabilinde 🙂
👉🏻Geçici kopya erişilebilir olduktan sonra, S3 yönetim konsolu veye AWS CLI kullanarak bu objenin depolama sınıfını değiştirebilirsiniz. Bu işlem, objeyi kalıcı olarak istediğiniz başka bir S3 depolama sınıfına taşıyacaktır. Yani yukarıda belirttiğim belirli bir süre erişilebilir olma konusunu aşmış olacağız.
❗️ Ek bir bilgi olarak bu yapılan işlemlerde her bir restore işlemi sırasında veri geri çağırma ücreti uygulanıdığını belirtmek isterim. Ayrıca data erişilebilir olduktan sonra da yeni depolama sınıfına kopyalama işlemi de ekstra maaliyet olarak karşınıza çıkacaktır ve tüm bu api istekleri de ayrıca api isteği olarak maaliyet olarak gözükmektedir.
Şimdi gelelim fasulyenin faydalarına 🙂 Bu bahsettiğim adımları gerçekleştirdikten sonra artık objemizi istediğimi cloud providera taşınabilir hale getirmiş oluyoruz. Ama bir bucketınızda elbette 1-2 obje bulunmuyordur. Milyonlarca objenizin bulunduğu bucketlarda migration işlemi için önce bu restore© adımlarını her bir obje için gerçekleştirmeniz gerekecek. Tam bu noktada hayat kurtaran daha önce de bir yazımda konu aldığım S3 Batch Operations feature ı hayatımızı kolaylaştırıyor diyebilirim. Daha detaylı bilgi için dilerseniz Ajanda da Bugün: “AWS S3 Batch Operasyonları” ‘nı da okuyabilirsiniz. Bu feature ile restore işlemini , hatta dilersek copy işlemini bir job oluşturararak yapabiliriz.
Şimdi adım adım gelin bu behsettiğim işlemleri yapalım.
Restore İşlemi:
Bu işlemi manuel olarak obje obje gerçekleştirmek isterseniz Amazon S3 servisinde Bucket bölümüne giderek aşağıdaki gibi objeleri ne kadar süre restore un tutulacağını belirterek yapabilirsiniz👇🏻
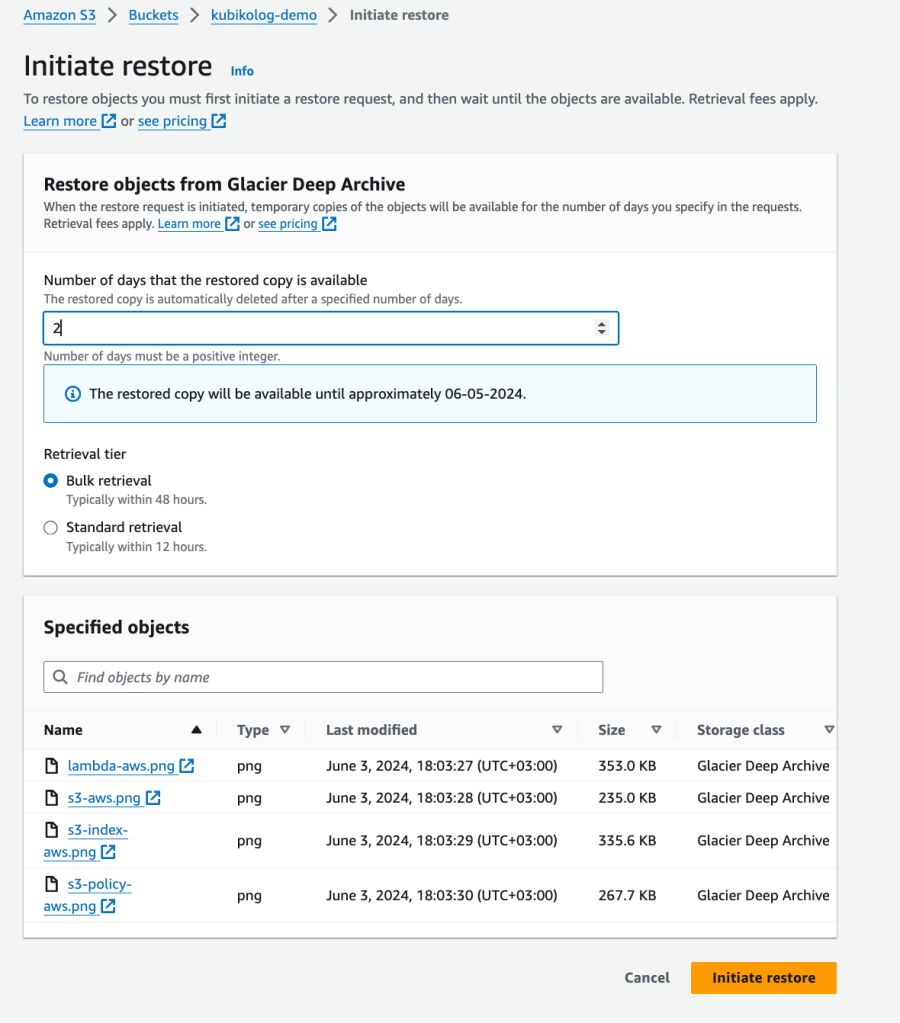
Burada karşımızda iki tip geri alma şekli çıkıyor: Bulk retrieval, Standard retrieval. Bulk retrieval maaliyet olarak en düşük olan ama geri yükleme süresi standarda göre uzun olan seçenektir. Büyük bir arşiv veya veri yedeği geri yüklemek istediğimizde ve bu verilerin hemen erişilebilir olmasının gerekmediği durumlarda Bulk Retrieval seçerek ilerleyebiliriz. Bizim için de bu seçenek uygun gözüküyor. Bu işlem tamamlandıktan da sonra da restored copy süresi bitmeden datayı kopyalamamız gerekecek.
💥💥Şimdi gelelim bu işlemi S3 Batch Operations ile birçok parquet için tek seferde yapmaya💥💥
Öncelikle konsoldan S3 Batch Operations servisine gidelim. Burada create job diyerek ilerlememiz gerekiyor. Aşağıdaki gibi açılan pencereden işlem yapılacak parquet lerin hepsini CSV formatında kaydederek yüklememiz gerek.
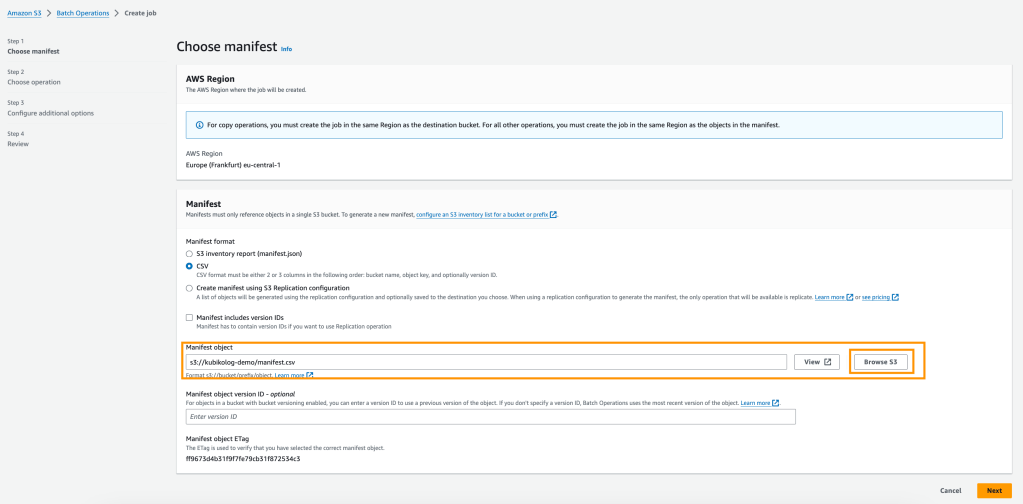
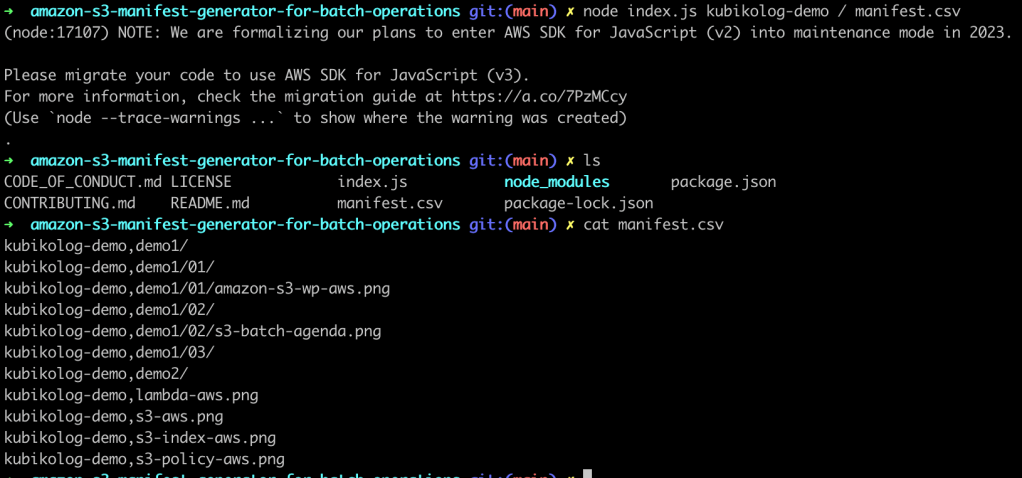
Burada parquet listemiz kabarık ise işin rengi hoş olmuyor tabiki. Bizim de çok sayıda taşınacak klasör klasör ayrılmış archive datamız olduğu için burada bu işlemi yapacak bir manifest generator kullandık. Github linkindan bu minik yazılımı indirerek kolaylıkla manifest.csv dosyasını oluşturacağız. Tüm Batch operasyonlarınız için bu generatoru kullanabilirsiniz.
git clone https://github.com/kubrakus/amazon-s3-manifest-generator-for-batch-operations
cd amazon-s3-manifest-generator-for-batch-operations
npm installManifest Generator kurulduktan sonra örnekteki gibi bucketınıza ait manifest.csv dosyasını oluşturabilirsiniz. Burada folder bazlı da bu manifest içeriğini üretmek mümkün.
Not: CLI üzerinden AWS’e erişmek bucketlerınızı görüntüleyebilmek için AWS CLI ‘yı indirmeniz gerekiyor.
Şimdi oluşturduğumuz manifest dosyamızı bucket içerisine upload edelim.
aws s3 cp manifest.csv s3://kubikolog-demo/Artık Batch Operation job ı create etmek için gereksinimlerimizi tamamladık. Önceki görselde belirttiğim browse S3 butonuna tıklayarak aşağıdaki resimde görüldüğü şekilde manifest.csv dosyamızı seçerek ilerleyeceğiz.
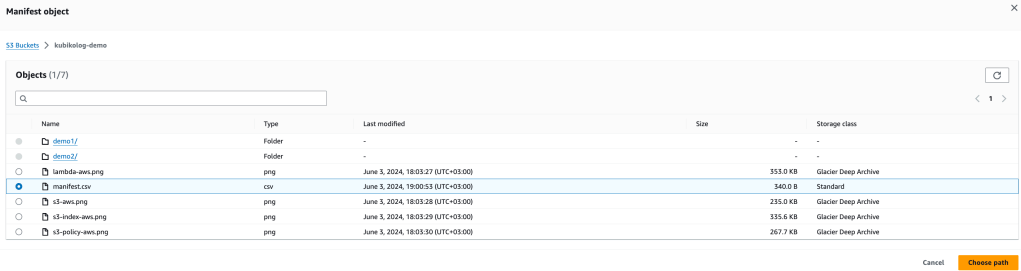
Bir sonraki adımda karşımıza hangi operasyonu gerçekleştirmek istediğimiz çıkıyor ve restore seçerek devam ediyoruz. Manuel restore işleminde de tanımladığımız restored copy nin saklanma süresi ve restore tipini seçerek ilerletiyoruz.
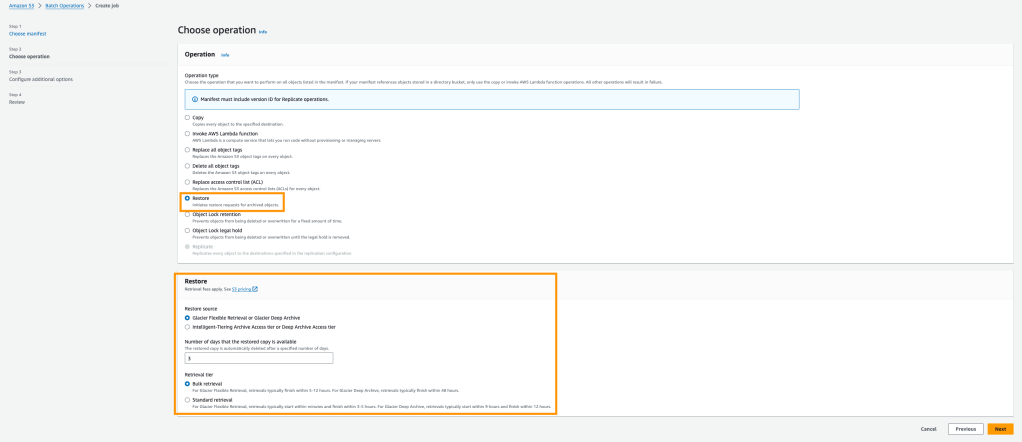
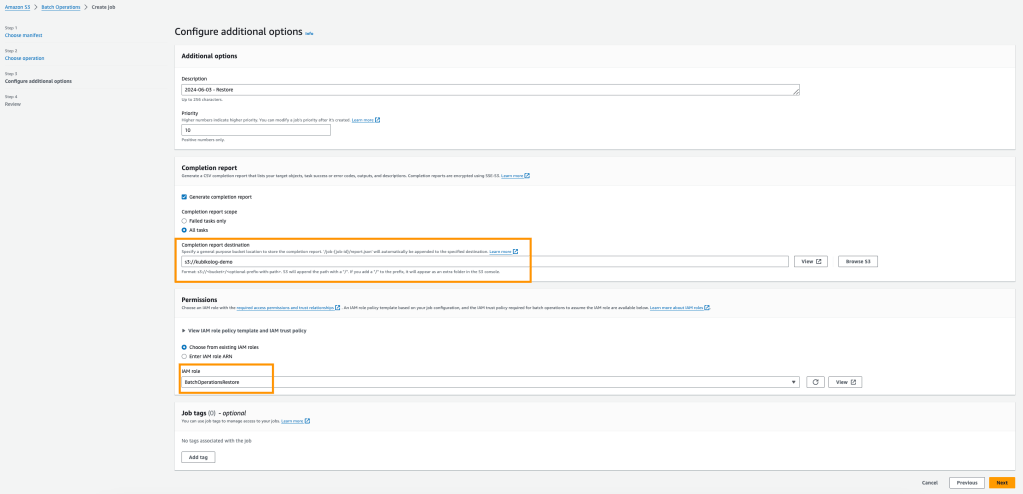
Bir sonraki adımda işlem tamamlandığında raporu oluşturacağı adresi tanıplayıp ilgili IAM role ü seçerek jobı create edelim.
Not: Burada gördüğünüz üzere “BatchOperationsRestore” role ü seçilmiştir. Bu işlem için bu role ekli değil ise önce IAM panelinden eklenmesi gerekmektedir. Tüm bucketlar için ya da seçili bucketlar için işlem izni verilerek ilerleyebilirsiniz.
Evet, artık jobımız hazır. ✅

Jobun çalışması için sob bir adımımız kaldı. Job a tıklayarak run diyoruz ve artık restore operasyonumuz başladı.

Artık objelere girip baktığınızda açıklama kısmında restore in progress ifadesini göreceksiniz. Tamamlandıktan sonra da expire date i yazıyor olacak.

Bu işlem datalarınızın boyutuna göre biraz sürecek. Tamamlandıktan sonra hem job ekranından hem obje içerisinden restore un tamamlandığını kontrol edebilirsiniz.

Ardından artık dataları copy işlemine geçebiliriz.
Copy İşlemi:
Aşağıdaki komut ile kubikolog-demo bucket’ındaki demo1 klasöründeki tüm dosyaları ve alt klasörleri kubikolog-demo-std bucket’ındaki demo1 klasörüne kopyalayacağız. Kopyalanan tüm dosyalar hedef bucket’ta STANDARD depolama sınıfında saklanacak.
aws s3 cp s3://kubikolog-demo/demo1/ s3://kubikolog-demo-std/demo1 --storage-class STANDARD --recursive --force-glacier-transferTüm bu işlemden sonra artık datalarımızı migration işlemi için standart storage class tipinde kaydetmiş olduk.
Şimdi migration işlemini gerçekleştirebiliriz. 🧬
Migration İşlemi:
Huawei Cloud konsoluna giriş giriş yaptıktan sonra Object Storage Service’ini açalım. Burada migration işlemi için oluşturulmuş bir feature yer almaktadır.
❗️Migration işlemi için hem Amazon S3 tarafına hem de Huawei OBS tarafına erişim için access key ve secret bilgisine ihtiyaç duyulmaktadır. Bu bilgileri girerek ve source – destination bucketları seçerek migration işlemini ilerletebiliriz.
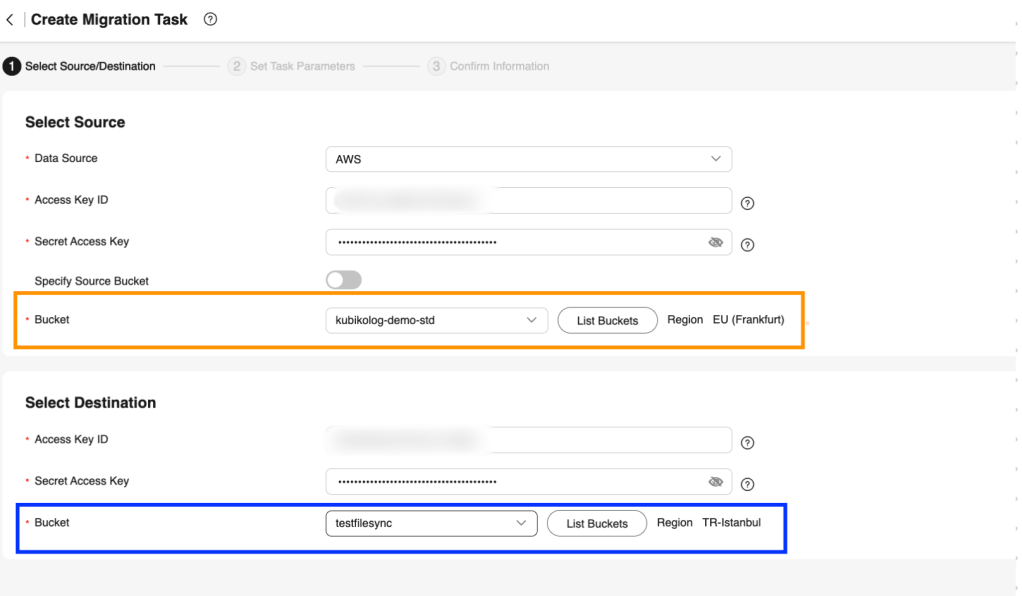
Bir sonraki ekranda çeşitli parametrelerin özelleştirilebildiği sekme yer alıyor. Source yapılandırmasında, taşıma yöntemini (dosya/klasör, nesne listesi, nesne adı öneki veya URL listesi), source bucket’ı ve taşınacak nesneleri seçebilirsiniz. Ayrıca, nesne metadata’sını taşıma ve seçmeli taşıma yapma seçenekleri bulunur. Hedef yapılandırmasında veri şifreleme, belirli bir prefix ve depolama sınıfı ayarları yapılabilir.
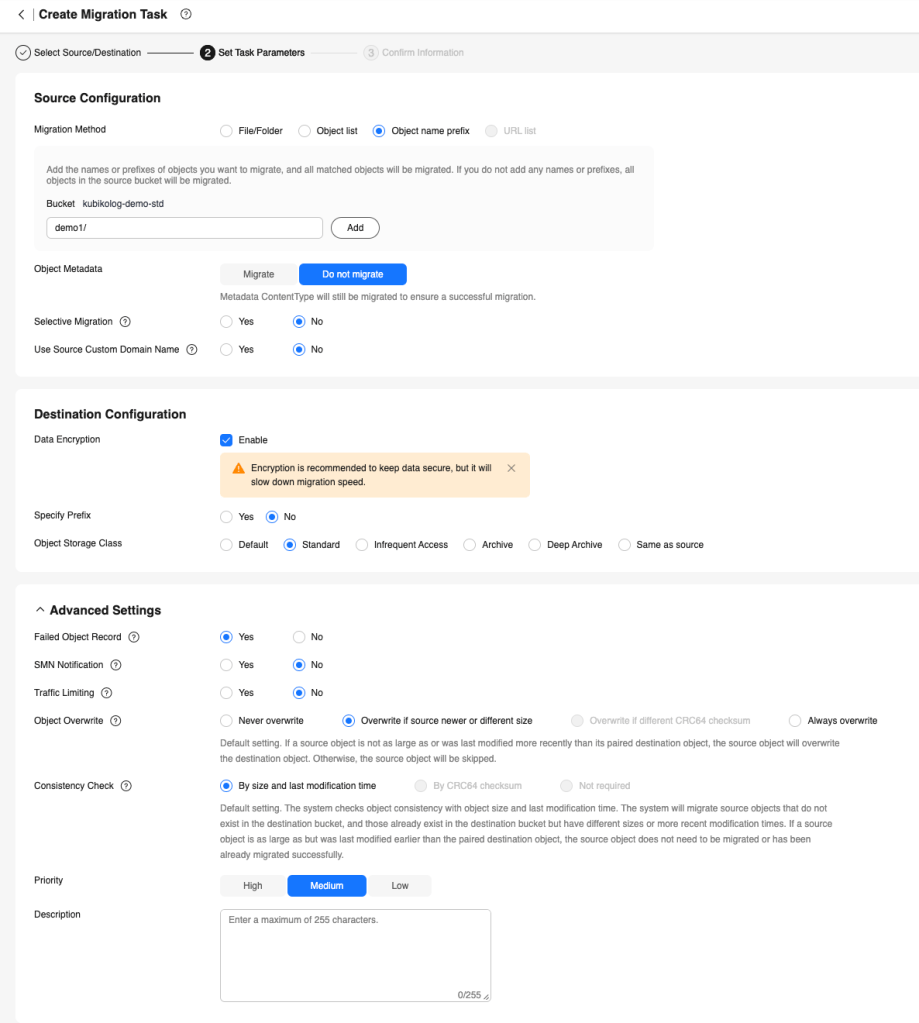
Migration taskını başlattığında tasks sekmesinden statüsünü kontrol edebilirsiniz. Tamamlandığnda taskın aşağıdaki completed olduğunu görebilirsiniz.
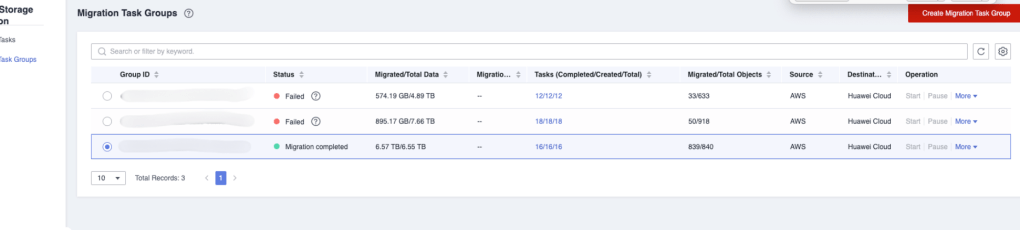
Bu arada Migration Tasks ve Migration Task Groups diye iki seçenek bulunmaktadır. “Migration Tasks”, tekil veri taşıma işlemlerini temsil ederken, “Migration Task Groups” ise bu işlemleri organize etmek ve yönetmek için bir araya getirilmiş görev gruplarını ifade eder. Tekil migration görevleri belirli veri setlerinin veya nesnelerin kaynaktan hedefe taşınmasını sağlarken, task grupları benzer görevleri bir araya getirerek taşıma sürecini daha sistemli ve etkin hale getirir. Bu yapı, büyük ölçekli veri taşıma operasyonlarını daha yönetilebilir ve organize edilebilir kılar.
İki Cloud provider arası data migration işlemini başarıyla tamamladık dostlar ✅
Şimdi sizleri KübikFM’ playlistinden dinlerken kanepede şekerleme yapmalık şarkısıyla başbaşa bırakıyor, iyi uykular diliyorum 🐸
