16-17 Haziran 2019
Korona yoktu, kanımız deli akıyordu o zamanlar arkadaşlar 🙂 Hadi kahvenizi alın, sizinle biraz gezelim.
Rotamız tarihiyle meşhur şehir: Roma.
2019 senesi benim için leyleği havada gördüğüm seneydi diyebilirim. Roma da bu seneden nasibini almış güzide şehirlerimizden. Normalde seyahatlerimi en erken 1 hafta öncesi planlarım ya da planı yola çıkarken yapmayı tercih ederim. Bu tarz şipşak gezilerin de avantaj ve dezavantajlarını bir başka yazımda bahsedeceğim. Roma gezime gelecek olursak, ilginç bir şekilde aylaaaaar öncesinde planladığım bir gezi. O zamanlar benim için düşük bütçeli seyahat zamanları. Ama ben yürek yiyerek bir otelden yer ayırtmışım. Son güne kadar da iptal etmeyi düşündüğüm bir otel idi. Kalacağınız yerden beklentiniz temiz bir yatak ve uyuyabilmek ise tavsiye edebilirim.
Otelin ismi: Backpackers Piramide. 1 gece için 22.50€ ödemiştim. Booking.com’ dan önceliğimin puanı yüksek, konaklamanın ucuz olanından filtreleyerek bulduğum bir otel. Wifi de fena çekmiyordu. Wifi demişken İtalya’da her şey gibi internet kullanım ücretinin de çok pahalı olduğunu belirtmek isterim. Polonya’da yüklediğim 100 zloty’lik kontör ile 1.5 ay Avrupa’yı gezdim. Yalnızca 30 zloty harcadım. İtalya’ya geldim ve 65 zloty 2 gün içinde bitiverdi. Ayrıca diğer Avrupa ülkelerinde puplic wifi noktaları çok yaygın. Ama özellikle Roma başta olmak üzere İtalya için bu durum geçerli değil. Bu sebeple benden tavsiye İtalya’yı gezerken paranız ve pasaportunuz gibi internetinize de sıkı sıkı sahip çıkın 😉
Toplam gezi sürem 2 tam gündü. Yeterli mi derseniz bence imkanınız ve zamanınız var ise 1 gün daha gezebilirsiniz. Ben tek başıma gezdiğim için zamanımın çoğunu görülmesi gereken önemli yerlere ayırıp, yemeği takeaway tercih ediyorum. Dinlenme kısmını da gezi bitinceye bırakıyorum. Bu sebeple benim 2 günüm sizin için 3 gün desek daha ideal olabilir.
Gelelim rotamıza!
Polonya’dan İtalya’ya uçak ile geçtim. Roma biletleri pahalı olduğu için önce Milano’ya uçtum. Ayrıca bahaneyle mini bir Milano turu da yapmak istemiştim. Onu da ayrı bir yazıda bahsetmeyi umuyorum. Neyse Milano’dan otobüs ile Roma’ya geçtim. Geceleri otobüs yolculuğu yapmayı tercih ediyorum. Bu sayede kalacak yer mevzusunu çözmüş oluyorsunuz : ) Otobüste nasıl uyunur? Konfor alanı dışında konfor alanı nasıl oluşturulur? Bununla ilgili de küçük tüyoların olduğu bir yazı ilerleyen zamanlarda gelecek.
Milano’dan 22.30 sularında başlayan yolculuğum ertesi sabah 7.45 sularında Roma Tiburtina Otobüs Terminali’nde sona erdi. Yola tek başına çıkıp yolda en az 1 Türk ile tanışmak gezilerimin olmazsa olmazımdır. Bu sefer 1 Brezilyalı ve 1 Türk ile tanışarak seyahatime bir tutam renk kattım diyebiliriz. Otobüste tanıştığım 2 güzel insan ile gezinin geriye kalan kısmını geçirdik. Sabah 8 gibi indiğimiz otobüs terminalinden öncelikle otellerimize yerleşmeyi tercih ettik. Zaten sırtımızdaki çantalar ile Haziran ayının kavurucu sıcağında gezmek mantıklı değildi. Benim otelim Kolezyum’a 15-20 dkka yürüme mesafesindeydi. Bu sebeple gezimin ilk durağı Kolezyum oldu.
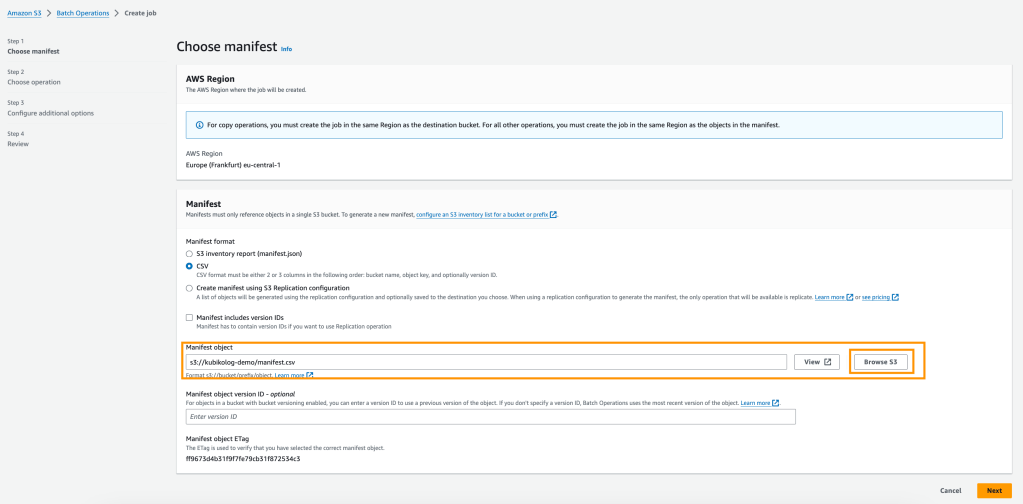
İtalya’nın en önemli tarihî miraslarından biri olan Kolezyum veya diğer adıyla Flavianus Amfi Tiyatrosu. Kesinlikle Roma’nın en popüler yeri. Roma’nın sembolü olarak bilinen bu yapı zamanında gladyatörlerin dövüştüğü bir yermiş. Aşırı kalabalık oluşundan dolayı içeriye girmek için kuyruğu beklemek istemedik ve dışarıdan instagramlık fotoğraflarımızı çekip yolumuza devam ettik. Tanıştığım 2 gezgin ile tercihimiz çoğunlukla yürüyerek gezmek olsa da yürümeyi tercih etmek istemeyenler için metroyla Colosseo durağında inerek Kolezyum’a gelinebilir.
Kolezyum giriş ücreti 12€, sıra beklemeden girmeyi sağlayan super bilet ise 16€.

1 Brezilyalı, 2 Türk ve Kolezyum Hatırası 🙂
Kolezyum’un hemen dibinde yer alan tarihi yerleri gezmeye başladık. Tarih demişken Roma zaten başlı başına destansı bir tarih bildiğiniz gibi. Karşınıza sürekli antik yapılar çıkıyor. Tarih severlerin aşık olacağı bir şehir diyebilirim. Açıkçası gezi süresince yeter bu kadar tarih dediğim anlar oldu. Ama o anda sokağın bir kenarından duyulmaya başlayan müzik sesleri ile hemen fikrimi geri aldım. Bir de sokak sanatçıları.. Her birinin apayrı yeteneği var. Tek kelime ile muazzam.



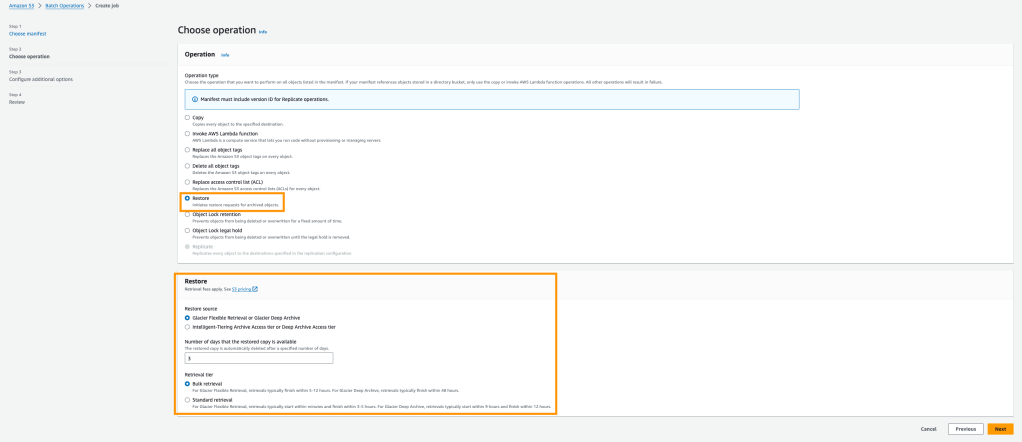
Gelelim gezimizin devamına; Kolezyum’un hemen yanında bulunan Zafer Takı ve Roma Forumu ile gezimize devam ettik. Roma Forumu (Foro Romano), eskiden Roma’nın şehir merkezi konumundaymış, ticaretin, siyasi ve dini işlerin yönetildiği yermiş. Sonra Palatino Tepesi‘ne devam ettik. Bir sonraki durak ise Circus Maximus. Burası da antik bir hipodrummuş. Öğlen 12.30 gibi Kolezyum ile başladığımız rotamız 16.00 gibi acıkma molasına giriyor. Sabah check-in saatinden önce otele gittiğim için eşyalarımı bırakmıştım ama odama yerleşememiştim. Bu sebeple hem eşyalarımın güvenliğinden emin olmak (^^) hem de check-in için otele geri döndüm. İşlerimi hallettikten sonra internetteki yorumlara göre yakınımızdaki Pizza alabileceğimiz mekana karar verdik: Pizzeria Ostiense. Tam fiyatı şu an hatırlamamakla beraber genel olarak 2 gün boyunca yediğimiz dilim pizzaların fiyatı 3-5€ arasındaydı.

Zafer Takı 
Roma Forumu
Ardından rotamızı Aşıklar Çeşmesi‘ne (la Fontana di Trevi) çevirdik. Rotaya doğru giderken Trajan Forumu (Foro di Traiano) olarak bilinen noktaya da uğradık. Burası imparatorluğun son meydanıymış. Ardından yürüyüşümüz Piazza Venezia yani Venedik Meydanı‘na kadar sürmüş oldu. Bu meydana vardığınızda devasal bir abide ile karşılaşıyorsunuz: Vittorio Emanuele II Abidesi. Bu abide İtalya’nın ilk kralı Vittorio Emanuele II için yaptırılmış. Romalılar bu anıtı sevmemiş ve ‘Roma’nın Takma Dişleri’ ‘Düğün Pastası’ gibi isimler ile buraya hitap etmişler. Romalıların aksine ben burayı bayağı sevdim 🙂 Merdivenlerinden yukarı çıktığınızda çok güzel bir Roma manzarası sizleri karşılıyor. Fotoğraf severler için birebir 😉


Meydandan devam ederek Via Del Corso isimli ünlü caddeye ilerliyoruz. Bu caddeye girdiğimizde sağ tarafımızda Aşıklar Çeşmesi (la Fontana di Trevi) yer alıyor. Çooook kalabalıktı çoook. İnternetteki fotoğraflara bakınca ben yanlış yere mi gittim dedim sonrası. Çünkü kalabalıktan yapıtın detaylarını inceleyemedim açıkçası. Ama Roma yılın her mevsimi kalabalık bir şehirmiş. Tabii şu an Korona sürecinde nasıldır bilemiyorum. İnanışa göre; çeşmeye arkanızı dönerek sağ elinizle sol omzunuz üzerinden para atar ve dilek dilerseniz hem dileğiniz kabul olurmuş hem de Roma’ya tekrar gelirmişsiniz. Denemedim 😛 Zaten denesem de kalabalıktan dolayı bence suya düşmezdi o para.

Aşıklar Çeşmesi (la Fontana di Trevi)
19.30 gibi Aşıklar Çeşmesi’nden ayrılıyor ve İspanyol Merdivenleri’ni (Piazza di Spagna) görmek üzere yürümeye devam ediyoruz. Tüm gün doymak bilmeyen Brezilyalı arkadaşımız bu sefer de dondurma alalım fikrini öne sürünce Gelato g Italino isimli ünlü dondurmacı dükkanından dondurma almaya niyet ediyoruz. İçeri girip fiyatları görünce fikrimizden vazgeçtik 🙂 20.00 gibi İspanyol Merdivenleri’nin olduğu alana vardık. Daha da kalabalık yer ömrü hayatımda yalnızca YTÜ yemekhanesinde gördüm arkadaşlar 😦 YTÜ’lü olanlar bilir orta bahçeye uzanan kuyrukları.. Şöyle ki, burası insanların buluşmak için kararlaştırdığı, merdivenlerde oturup bir şeyler yiyip içtiği bir alanmış. Biz de tam saatinde gittiğimizi düşünürsek kalabalık olması normal. Burayı daha sakin bulmak için bence sabah saatleri tercih edilebilir. Aynı şekilde bu fikrim Aşıklar Çeşmesi için de geçerli. Ama kesinlikle 2 yere de öğle vakti gitmeyin. Giderseniz şimdiden başınıza geçen güneşten ben sorumlu değilim 🙂 Gelelim İtalya’da İspanyol Merdiveni’nin neden bulunduğuna. o alanda İspanya Konsolosluğu yer aldığından meydanın ve merdivenlerin isim annesi olmuş diyebiliriz. Biz de merdivenlerde bir süre oturduk ve sabah 1€’ya aldığımız stok muzlarımızı yedik 🙂

İspanyol Merdivenleri (Piazza di Spagna)
Her gezi günün sonunda kaç km yürüdüğüme bakarım. 30 km yürüdüğümüz bir gün olmuş arkadaşlar. Bence 1 gün için gayet iyi 🙂 O zaman Roma’da 2.güne başlamak için dinlenme zamanı gelmiş. İspanyol Merdivenleri’nden otele yürüyemecek kadar yorulduğuma karar vererek metro kullandım. MEA olarak geçen kırmızı metroyla Spagna durağından binip Vittorio Emanuele durağında MEB1 metrosuna geçiş yaptım. MEB1 metrosuna Termini durağından binmiş oldum ve Piramide durağında indim. Otelim bu istasyona yaklaşık 450 m uzaklıkta. Ayrıca MEB1 metrosu şehirlerarası otobüs terminaline de gidiyor. Bu sebeple otelim hala en uygun fiyatlı oteller arasındaysa tercih edebilirsiniz.
2.günün planında ilk olarak dün gezemediğimiz Pantheon geliyor. Via Del Corso isimli ünlü caddenin sol tarafında yer alan bu meşhur tapınağı ücretsiz olarak gezebilirsiniz. Ama içeri girmek için biraz uzun beklemek zorunda kalacaksınız. Değer mi? Değer. Burası kralların, ressamların ve mimarların gömülü olduğu bir mezar yeri. Pantheon, betondan yapılan ve desteksiz olan dünyanın en büyük kubbesine sahip. Yapının kubbesi delik bir yapıda. Bu deliğin ismi Oculus. Güneşli günlerde kubbedeki bu delikten giren güneş penceresiz mahzeni aydınlatırken, yağmurlu günlerde bu kubbeden giren yağmur damlaları yerde bulunan minik deliklerden dışarı atılıyor. Gerçekten sıradan olmayan bu yapı görülmeden dönülmemesi gereken bir yer.



Pantheon’un ardından Roma sokaklarında bir süre akışına dolaşabilirsiniz. Vespa’lar ve Fiat 500’leri göreceğiniz dar sokaklar, filmlerdeki sahneleri anımsatabilir. Random dolaşırken Roma pazarına denk düşmeniz de mümkün, bizim gibi. Pazar içerisinde gezerek değişik tadımlar yapmanız münkün. Bazı pazarcılar ikram konusunda bonkör 🙂 Ek olarak, sonradan araştırınca öğrendim ki tesadüfen denk geldiğimiz bu pazarın orası Çiçek Tarlası yani Campo de Fiori olarak adlandırılıyormuş.
Ardından Piazza Navona’ya rotayı çevirdik. Bulunduğumuz konuma yakın oldukça ünlü bu meydanda 3 adet çeşme bulunuyor. Meydanda bulunan çeşmelerin en ünlüsü Bernini’nin yaptığı Dört Nehir Çeşmesi (Amerika’da Rio de la Plata, Avrupa’da Tuna, Asya’da Ganj, Afrika’da Nil Nehri). Meydanı etrafı kafeler ile dolu. Ayrıca kulağınızda müzik sesleri de eksilmiyor.


Buraya kadar hep Tiber Nehri’nin doğu yakasını gezdik. Gezimin devamı Dünya’nın en küçük ülkesi olan Vatikan. Vatikan’ı ayrı bir yazıda size anlatmak istiyorum. Şimdilik hikayeyi burada keselim. Yakında Vatikan ve gelecek diğer yazılar ile görüşmek üzere..
Sağlıklı ve gezili günleriniz olsun!