

Merhaba, bir önceki yazımda Ceph storage cluster kurulumu yapıp ardından daemon konfigürasyonları yapmıştık. Bugünkü yazımızda da konfigürasyonlara devam edeceğiz ve sık kullandığım komutları paylaşacağım. Bi önceki yazıya buradan ulaşabilirsiniz.
MON Konfigürasyonları
Ceph monitörleri (MON’lar), istemcilerin MON ve OSD nodelarını bulmak için kullanılan cluster haritasını saklar ve sürdürür. Ceph istemcileri, herhangi bir veriyi OSD’lere okumadan veya yazmadan önce cluster haritasını almak için bir MON’a bağlanmalıdır. Bu nedenle, cluster MON’larının uygun şekilde yapılandırılması kritik öneme sahiptir.
MON’ların her biri aşağıdaki rollerden birine sahip olur. Bu yapılandırma ile kendi içindeki yönetimi yapar diyebiliriz.
Leader: Cluster haritasının en son sürümünü alan MON.
Provider: Cluster haritasının en son sürümüne sahip olan ancak leader olmayan MON.
Requester: Cluster haritasının en son sürümüne sahip olmayan ve quorum a yeniden katılabilmesi için bir provider ile eşitlenmesi gereken MON.
- MON Quorum statüsüne aşağıdaki iki komuttan birini tercih ederek bakabiliriz.
$ ceph mon stat
$ ceph quorum_status -f json-pretty- Clusterın genel konfigürasyonlarını görmek için aşağıdaki komutu kullanabiliriz.
$ ceph config dump Cephx
Ceph, kimlik doğrulama için paylaşılan secret keyler kullanarak Ceph bileşenleri arasında kriptografik kimlik doğrulama sağlar. Bunun için ise Cephx denilen protokolü kullanmaktadır. Cluster cephadm kurulduğunda Cephx’i varsayılan olarak etkin gelmektedir. Gerekirse Cephx’i devre dışı bırakabilirsiniz, ancak cluster güvenliğini zayıflattığı için önerilmez. Cephx protokolünü etkinleştirmek veya devre dışı bırakmak için “ceph config set” komutunu kullanılır.
- Servis ve cluster kimlik doğruluma şeklini görüntülemek aşağıdaki komutlar kullanabilirsiniz.
$ ceph config get mon auth_service_required
$ ceph config get mon auth_cluster_required- Cluster içerisinde yer alan mevcut accountları listeler.
$ ceph auth list- Yeni bir user oluşturmak istersek aşağıdaki komutu kullanabiliriz. Kimlik doğrulama için, keyring dosyası gerekmektedir, Bir önceki yazımda da belirtmiştim. Bu nedenle ilgili dosyayı bu yeni kullanıcı hesabıyla çalışan clusterdeki tüm hostlara kopyalamamız gerekir.
$ ceph auth get-or-create kubikolog.user mon 'allow r' osd 'allow rw' -o /etc/ceph/ceph.kubikolog.user.keyring- Oluşturduğumuz userı silmek ister isek,
$ ceph auth del <kubikolog.user>Ceph tell
Ceph tell komutunu monitorün down olduğu durumlarda troubleshooting için kullanabilirsiniz. Kullanım şekli aşağıdaki gibidir.
$ ceph tell $type.$id config get ...
$ ceph tell $type.$id config set ...
ex:
$ ceph tell mon.* config set mon_allow_pool_delete trueOSD Konfigürasyonları
OSD bileşenleri veriyi kopyalayarak saklanmasında sorumludur. Serinin ilk yazısında datanın saklanma tiplerine değinmiştim. Bu yönetim OSD ile yapılır. Ayrıca monitore hostların disk durumunu da iletir. Her disk için ayrı bir disk tutulması önerilmektedir.
- Clusterda çalışan bir OSD’nin konfigürasyonlarını görmek için aşağıdaki komutu kullanabiliriz.
$ ceph config show <osd.1> - Bir OSD servisini restart etmek için ise aşağıdaki komut işe yarayacaktır.
$ ceph orch daemon restart <osd.1> - Serinin ikinci yazısının son cümlelerinde clustera yeni bir OSD eklemenin komutunu paylaşmıştım. Şimdi de bu eklediğimiz OSD’yi kaldırmayı deneyelim.
$ ceph orch daemon stop <osd.1>
$ ceph orch daemon rm <osd.1>
$ ceph osd rm <1>Hatırlatma: OSD ekleme komutu:
$ ceph orch daemon add osd <osd.1>:/dev/vdb - OSD ağacına bakmak için,
$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08817 root default
-3 0.02939 host nodec
0 ssd 0.00980 osd.0 up 1.00000 1.00000
1 ssd 0.00980 osd.1 up 1.00000 1.00000
2 ssd 0.00980 osd.2 up 1.00000 1.00000
-5 0.02939 host noded
3 ssd 0.00980 osd.3 up 1.00000 1.00000
4 ssd 0.00980 osd.4 up 1.00000 1.00000
5 ssd 0.00980 osd.5 up 1.00000 1.00000- Clusterdaki disk boyutunu görmek için,
$ ceph dfPool Konfigürasyonları
Poollar, nesneleri depolamak için mantıksal bölümlerdir. Ceph istemcileri nesneleri poollara yazar. Poollar, küme için bir dayanıklılık katmanı sağlar, çünkü poollar veri kaybetmeden arızalanabilecek OSD’lerin sayısını tanımlar.
Veri nasıl saklanır diye konuşacak olursak;
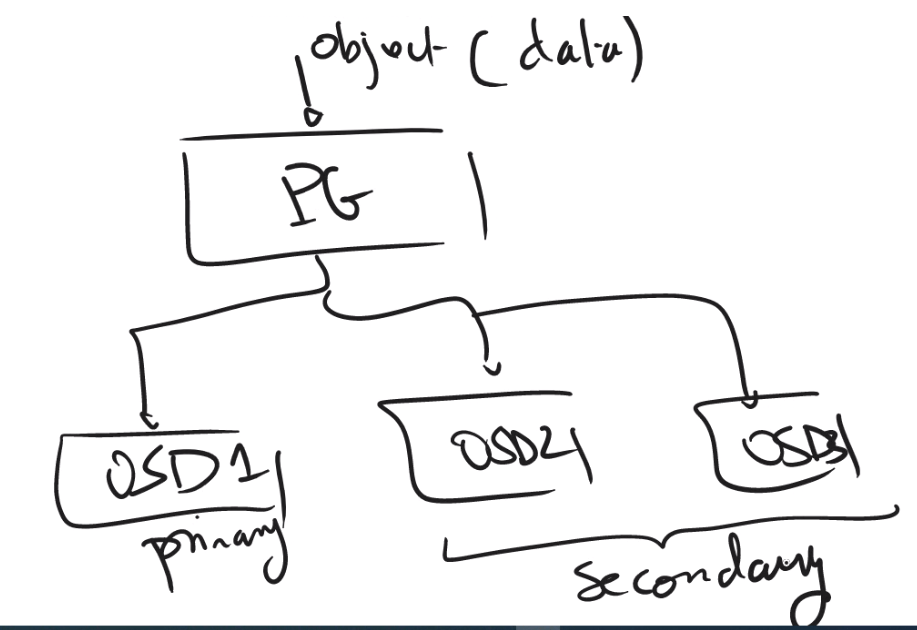
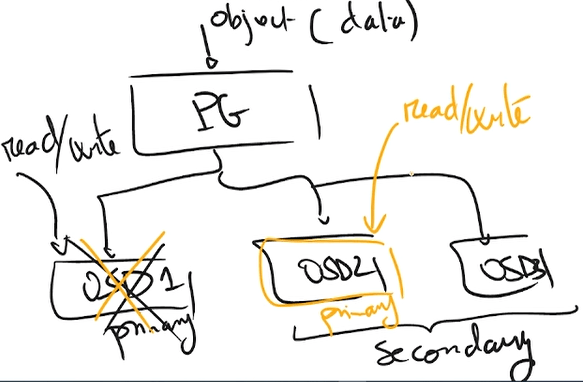
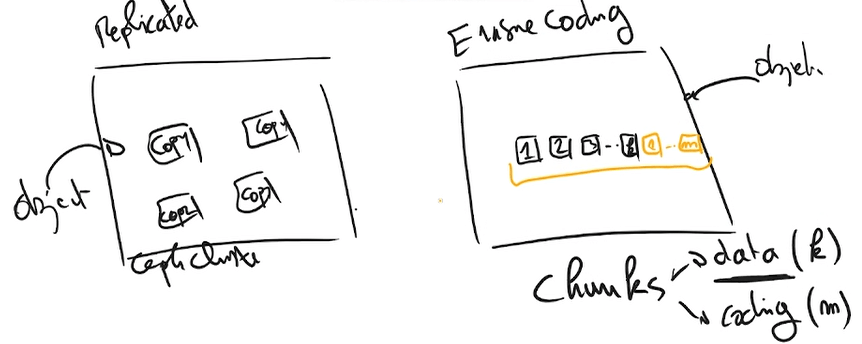
Verinin Ceph üzerinde bulunan pool adresine yazma talebinde bulunmasıyla süreç başlar. Ardından daha önce konuştuğumuz CRUSH algoritması çalışır ve PG ataması yapar. Ayrıca CRUSH algoritması kullanılacak PG’leri OSD’ler ile eşlemekten de sorumludur. Ardından da veri primary olarak belirlenen PG’ye dolayısıyla da primary OSD’ye yazılmış olur. Primary OSD’ye yazma işlemi tamamlanınca da belirtilen pool türüne göre yedekleme yapılır. Örneğin replicated pool ile ilerleniyorsa belirtilen kopya sayısına göre diğer OSD’lere yazma işlemi yapılır. Yedek OSD’ler CRUSH Map ayarlarına göre farklı sunucularda tutulacak şekilde yerleştirilir. Tüm kopyaların da yazma işlemi tamamlanınca işlem tamamlanmış olur. Mükemmel çizimimizi de şuraya bırakalım 🙂
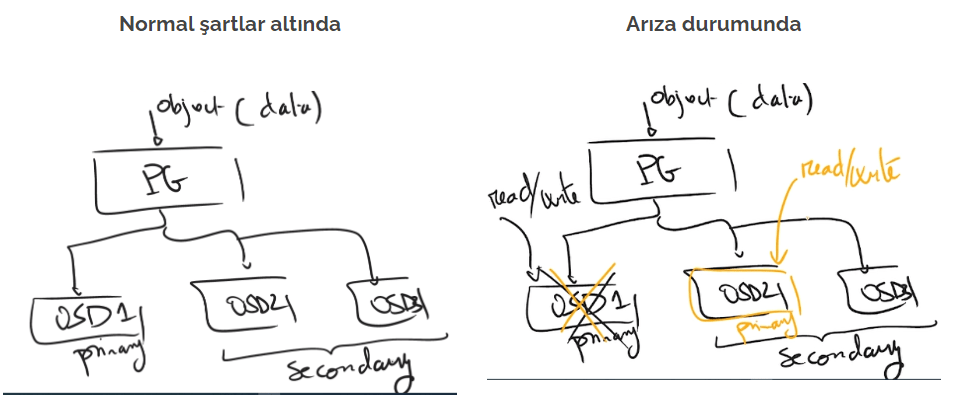
Şimdi gelelim fasulyenin faydalarına 🙂 Yukarıda verinin nasıl tutulduğunu konuştuk. Sıralamaya göre gidersek önce nasıl pool oluşturulduğuna bakmamız gerekecek.
- Aşağıdaki komutu kullanarak pool oluşturup, bu pool için pg sayısını atayabiliriz. Burada pg-num bu pool için ayrılmış pg sayısını, pgp-num da bu poolda efektif kullanılacak pg sayısını ifade eder. pfp-num=pg-num olarak set ediyoruz.
$ ceph osd pool create <pool name> <pg-num> <pgp-num>Pool oluşturururken replika sayısnı belirtmezsek default olarak 3 olarak pool’a atama yapar.
Total PG sayısını hesaplamak için aşağıdaki gibi bir formülasyon bulunuyor. Bunu sizin yerinize hesaplayan calculatorler de var tabi ki. Red Hat’in PG calculator linkini de şuraya bırakalım.
💡 Ceph Placement Groups (PGs) per Pool Calculator | Red Hat Customer Portal Labs
💡 Total PGs = (OSDs * 100)/Number of replicas
- Bir başka PG atama yöntemi olarak da target_size_ratio ‘dan bahsedebiliriz. Bu özellik ile clusterda bulunan poollara bir oran veriyorsunuz ve bu orana göre pg’ler poollara atanıyor. Yukarıda calculator linkinde de vardi. Burada tüm clusterdaki oranların toplamının 1’e tamamlayarak oranlamayı yapıyor. Bunun için aşağıdaki komutu kullanabilirsiniz.
$ ceph osd pool set <pool name> target_size_ratio <ratio>- Ceph’te kullandığımız ve kesinlike kullanmanızı önerdiğim autoscale_mode‘dan bahsetmek istiyorum. Bu modu açmanız halinde clusterdaki poolların pg sayısını total pg’lere göre oranlayarak paylaştırıyor. Burada her pool için verdiğiniz ratio değerine göre oranlama yapıyor. Bu yüzden de kullanışlı buluyorum. Bu modu aktif etmek için aşağıdaki komutları kullanabilirsiniz.
$ ceph mgr module enable pg_autoscaler
$ ceph osd pool set pool-name pg_autoscale_mode on- Benim en sık kullandığım bir diğer komut ise aşağıdaki komut. Bu komut ile pooların güncel pg sayılarını ve diğer konfigürasyonlarını listeleyebiliryorsunuz.
$ ceph osd pool autoscale-status- Tabii poolları da listelemek için komut bulunuyor. “ceph osd pool ls” komutu ile clusterdaki pool isimlerini listeliyorsunuz. Sonuna “detail” eklediğinizde ise özelliklerini de size getiriyor. Yani replika sayısını, target size ratio değerini, autoscale mode on/off mu gibi gibi.
$ ceph osd pool ls
$ ceph osd pool ls detailPool oluşturma işlemini Ceph’in bize sağladığı dashboard üzerinden de yapmamız mümkün. Komutlarla yaptığımız adımların arayüzden yapılma şekli aşağıda görsellerde belirtildiği şekildedir.


- Pool ismini değiştirmek istersek aşağıdaki komutu kullanabiliriz.
$ ceph osd pool rename <old-pool-name> <new-pool-name>- Pool oluşturmak gördüğünüz gibi gayet kolay. Ancak oluşturduğunuz pool’u kaldırmak bu kadar kolay değil. Kolay olmasın da zaten. Tehlikeli sular 🙂 Pool’u silmek için önce mon_allow_pool_delete özelliğini aktif etmek gerekiyor. Ardından silme komutlarını çalıştırmanıza izin veriliyor. Silme komutları aşağıdaki gibidir.
$ ceph config set mon mon_allow_pool_delete true
$ ceph osd pool rm <pool_name> <pool_name> --yes-i-really-really-mean-itHATIRLATMA !! Bu işlem sonrası silme işlemini tekrar false a çekmeyi unutmayın. Bir küçük hata çok üzebilir sonrası. Benden demesi.
$ ceph config set mon mon_allow_pool_delete falseYazının sonuna geldik sevgili Ceph sever okurum 🙂 Bu yazının üzerine biraz IT dünyasından uzaklaşmak lazım. Okyanuslara açılmaya ne dersiniz ? 🐸 Tesadüfen beni bulan bir vlog önerisiyle yazımı sonlandırıyor, sizi okyanusla baş başa bırakıyorum 😉
















{kind=link}